📝 Paper Summary
LLM-assisted scientific workflow
Automated literature review
Human-AI collaboration
LLM-based agents, particularly when using a consensus of high-performing models, can filter thousands of academic papers for systematic reviews with >98% recall in minutes rather than weeks.
Core Problem
Systematic literature reviews (SLRs) require manually screening thousands of papers based on titles and abstracts to identify relevant studies, a process that is labor-intensive, slow, and prone to fatigue.
Why it matters:
- Screening 8,000+ papers takes ~66 person-hours of uninterrupted work, often stretching to months in practice due to fatigue and other commitments
- Manual filtering suffers from inconsistency and human error, with standard error rates ranging from 0.5% to 9%
- The high cost of entry discourages broad exploratory surveys and cross-disciplinary analyses
Concrete Example:
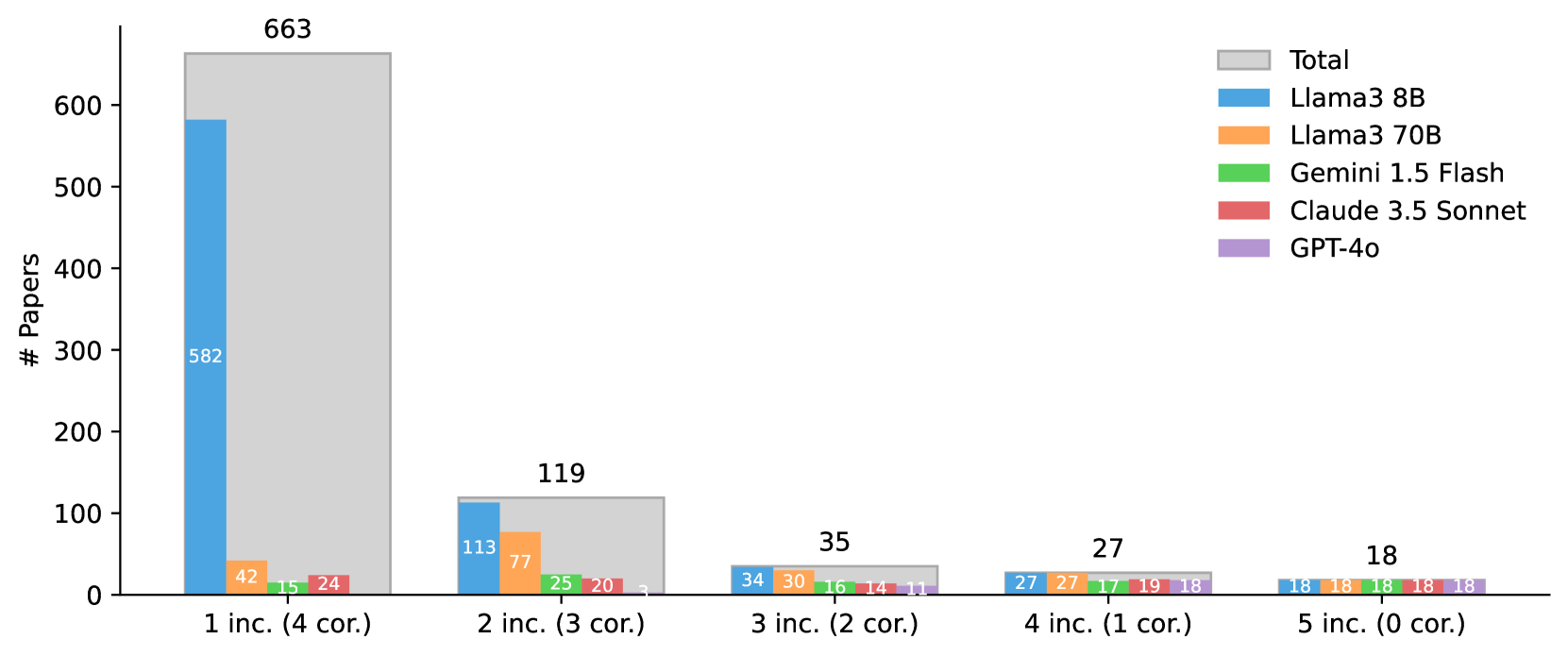
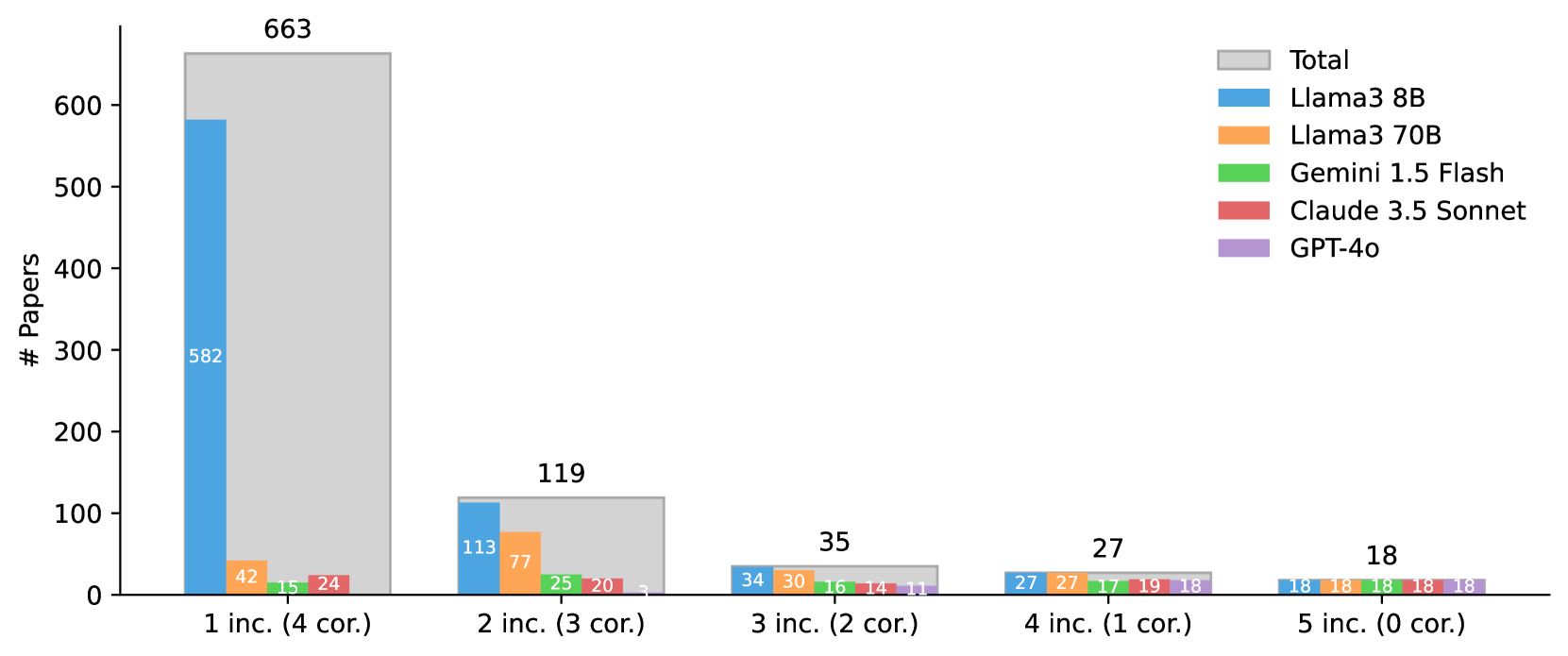
In the authors' case study of immersive visual network analysis, researchers had to screen 8,323 candidates. Manually, this took weeks. An individual LLM (Llama-3-8B) flagged 774 false positives, while a human reviewer might miss edge cases due to fatigue.
Key Novelty
LLMSurver: Visual-Interactive Consensus Filtration
- A structured pipeline where multiple LLM agents independently classify papers as 'Include' or 'Discard' based on title/abstract using detailed prompt criteria
- A consensus voting mechanism (e.g., 'Consensus Best') that combines outputs from top models (GPT-4o, Claude 3.5, Gemini 1.5) to maintain high recall while drastically reducing false positives
- A visual-interactive interface allowing researchers to iteratively refine prompts, inspect agent justifications, and resolve disagreements
Architecture
Screenshot of the LLMSurver application interface showing the dashboard layout.
Evaluation Highlights
- Consensus (Best) achieved 98.86% recall and 97.99% accuracy on a dataset of 8,323 papers, missing only 1 out of 88 relevant papers.
- GPT-4o processed the entire corpus in under 10 minutes for $28.81, compared to an estimated 66+ hours of human labor.
- Consensus voting reduced false positives from ~774 (individual Llama-3-8B) to 167, a 98% reduction in the manual validation workload compared to the raw search results.
Breakthrough Assessment
7/10
Strong practical application demonstrating that off-the-shelf LLMs can replace weeks of manual labor with high reliability. While the underlying ML technique is standard prompting, the system integration and rigorous validation against ground truth are valuable.