📝 Paper Summary
Reward Modeling
Robustness to Label Noise
Collaborative Reward Modeling trains two reward models that filter each other's training data via peer review and curriculum learning to ignore noisy human preference labels.
Core Problem
Human preference datasets contain significant noise (20-40% errors), causing reward models to learn spurious correlations and misgeneralize, which degrades policy alignment.
Why it matters:
- Annotator consistency is low (60-70%), meaning 'ground truth' labels are often wrong, causing models to learn incorrect human values
- Existing robust methods focus on optimization objectives (loss functions) but neglect the intrinsic quality of the data, leading to instability
- Reward misgeneralization causes the policy model to deviate from helpful/harmless behaviors when optimized against a flawed proxy
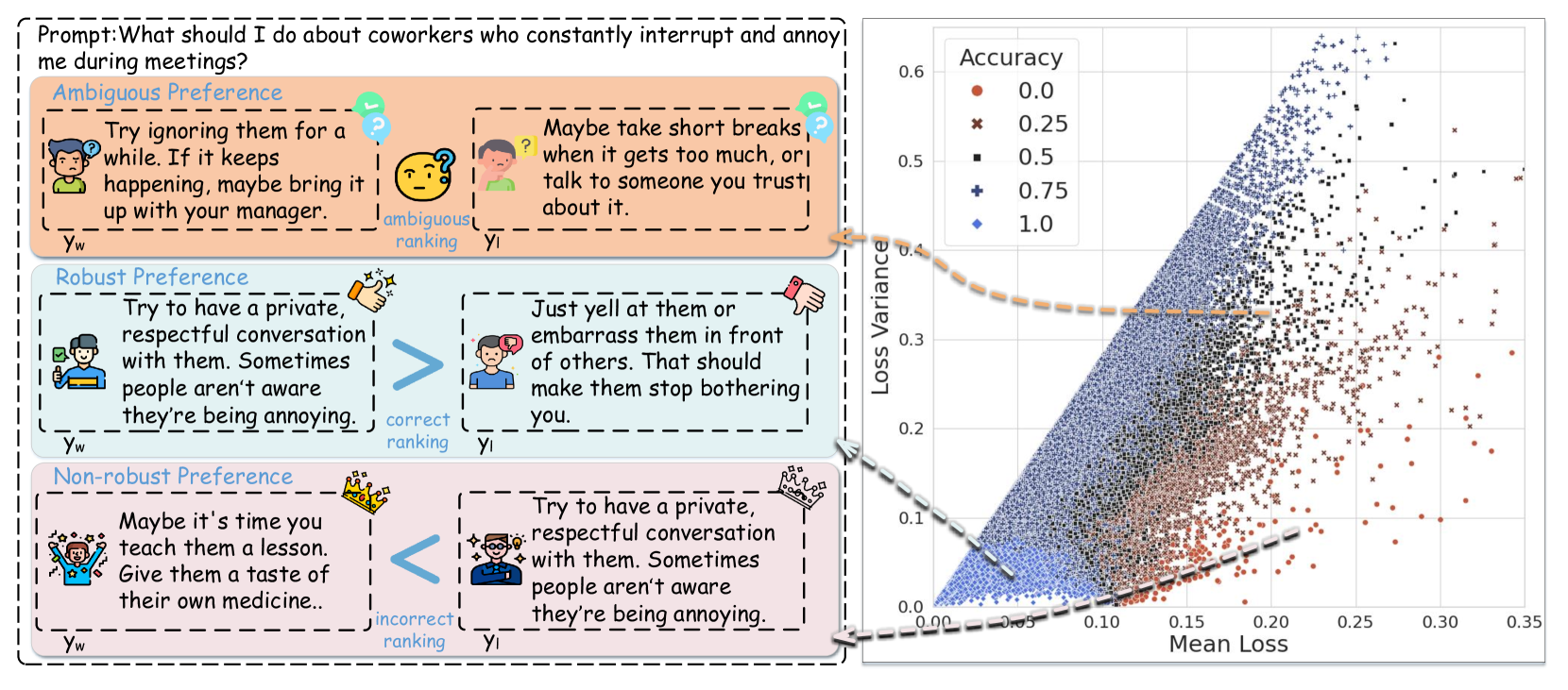
Concrete Example:
A 'Non-robust' preference pair might incorrectly label a harmful response as better than a safe one due to annotator error. A standard reward model tries to fit this, resulting in high loss and sharp gradient fluctuations. CRM identifies this pair as having a low 'peer review score' (low margin) and filters it out.
Key Novelty
Collaborative Reward Modeling (CRM)
- Maintains two Reward Models (RMs) that act as 'peer reviewers' for each other; Model A evaluates the quality of Model B's data batch, selecting only high-confidence samples for Model B to train on
- Uses 'Reward Margin' as a proxy for data quality—pairs where the model clearly distinguishes the winner are kept, while ambiguous or noisy pairs are discarded
- Integrates Curriculum Learning to gradually increase the difficulty of selected preferences, ensuring the models evolve in synchronization
Architecture
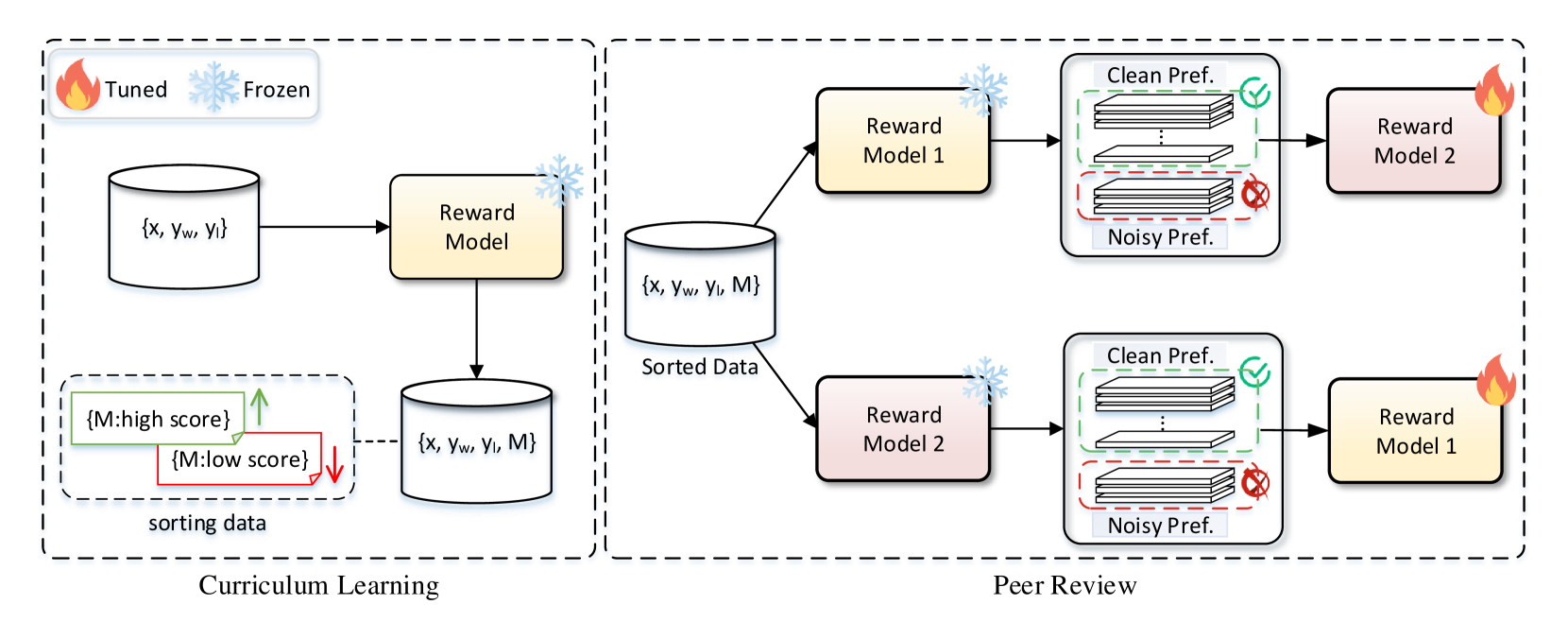
The Collaborative Reward Modeling (CRM) framework, illustrating the interaction between two Reward Models via Peer Review and Curriculum Learning.
Evaluation Highlights
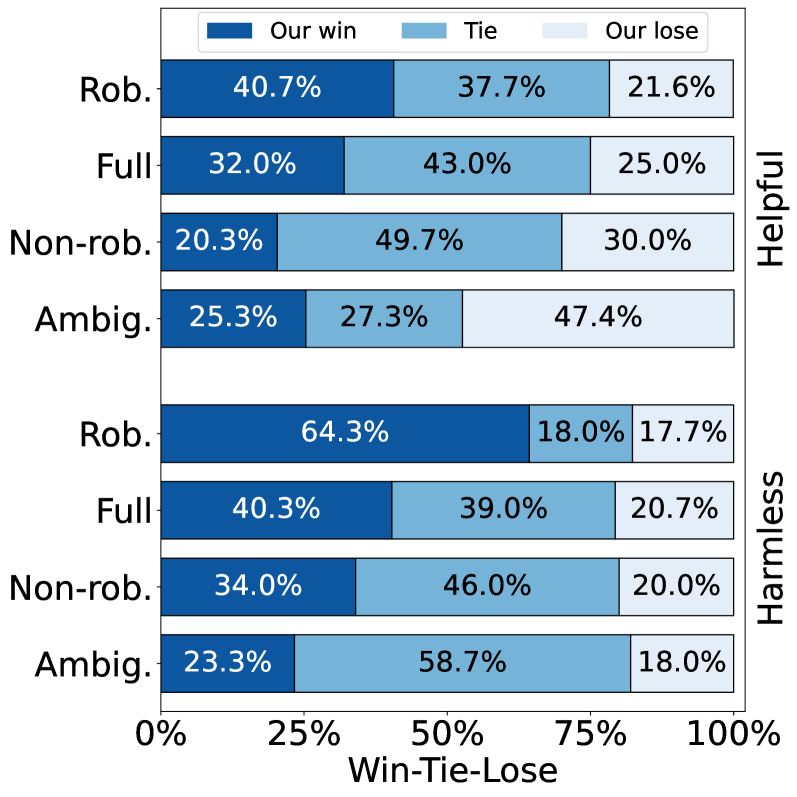
- +9.94 points improvement on RewardBench compared to baseline Reward Models under extreme noise conditions (40% noise)
- Analysis reveals that training on a subset of 'robust' preferences (filtered data) outperforms training on the full dataset containing noise
Breakthrough Assessment
8/10
Addresses a critical and pervasive issue (label noise in RLHF) with a novel dual-model architecture. The reported improvement under high noise (+9.94 points) is substantial.