📝 Paper Summary
Personalized Reward Modeling
Preference Alignment
CoPL personalizes LLM reward models by constructing a user-response graph to propagate preference signals via message passing and dynamically routing inputs to user-specific LoRA experts.
Core Problem
Existing personalized reward models struggle with sparse annotations because latent variable methods fail to align similar users if their annotated response sets are disjoint (do not overlap).
Why it matters:
- Users often provide very few preference labels, making it difficult to learn accurate individual profiles without leveraging similarities to others
- Standard methods map users with identical preferences to distant embedding points if they rate different items, preventing effective generalization
- Current approaches either rely on inflexible pre-defined clusters or fail to capture controversial preferences where user groups disagree
Concrete Example:
User 1 prefers A>B; User 2 prefers C>D. Even if they share the same underlying taste (e.g., preference for brevity), a standard latent model sees no connection between them because their annotated items {A,B} and {C,D} are disjoint. CoPL connects them via a graph (e.g., User 1 -> Item X -> User 3 -> Item Y -> User 2) to infer similarity.
Key Novelty
Graph-based Collaborative Preference Learning with Mixture of LoRA Experts
- Constructs a bipartite graph (Users <-> Responses) where edges represent preferences, allowing signals to propagate through multi-hop connections even when direct overlap is missing
- Uses the learned graph embeddings to gate a Mixture of LoRA Experts (MoLE), dynamically adapting the reward model's parameters to specific user profiles during inference
- Enables optimization-free adaptation for new users by aggregating embeddings from similar existing users found via graph neighbors, avoiding the need for retraining
Architecture
The overall training pipeline of CoPL. Left: User-Response Bipartite Graph Construction. Middle: GNN Message Passing to learn embeddings. Right: MoLE-based Reward Model using user embeddings for gating.
Evaluation Highlights
- Consistently outperforms personalized baselines (I2E, VPL, PAL) on both seen and unseen users across TL;DR, UltraFeedback-P, and PersonalLLM datasets
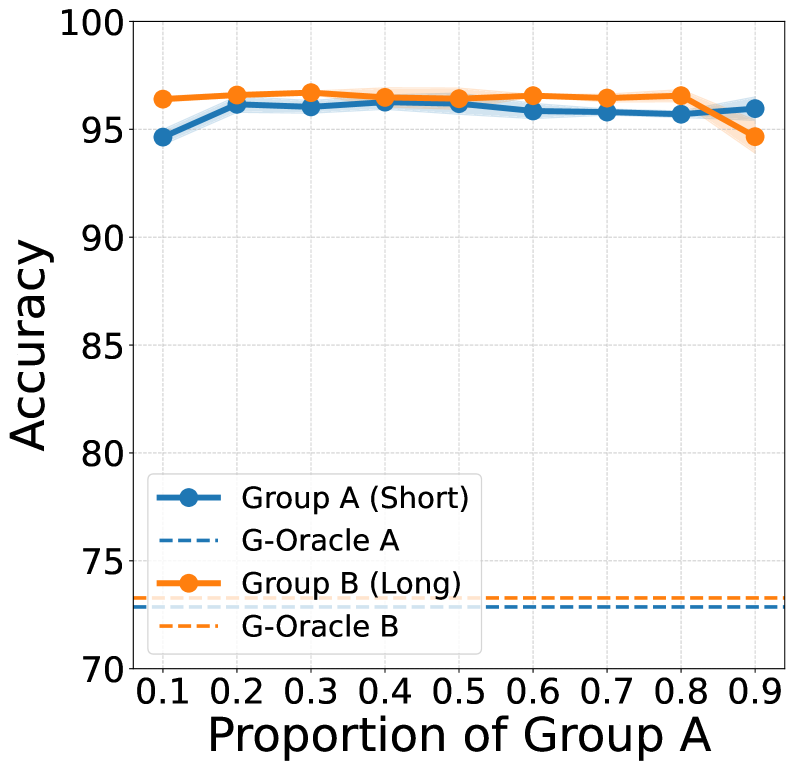
- Achieves performance comparable to a Group-Oracle (which has perfect knowledge of user groups) on controversial pairs where user preferences diverge
- Maintains robustness in sparse settings (e.g., only 8 annotations) where baseline performance typically degrades
Breakthrough Assessment
7/10
Clever integration of collaborative filtering (common in RecSys) into LLM alignment. Addresses the realistic 'sparse data' problem effectively. The optimization-free adaptation is a practical strong point.