📝 Paper Summary
Data Management for LLMs
LLMs for Data Management
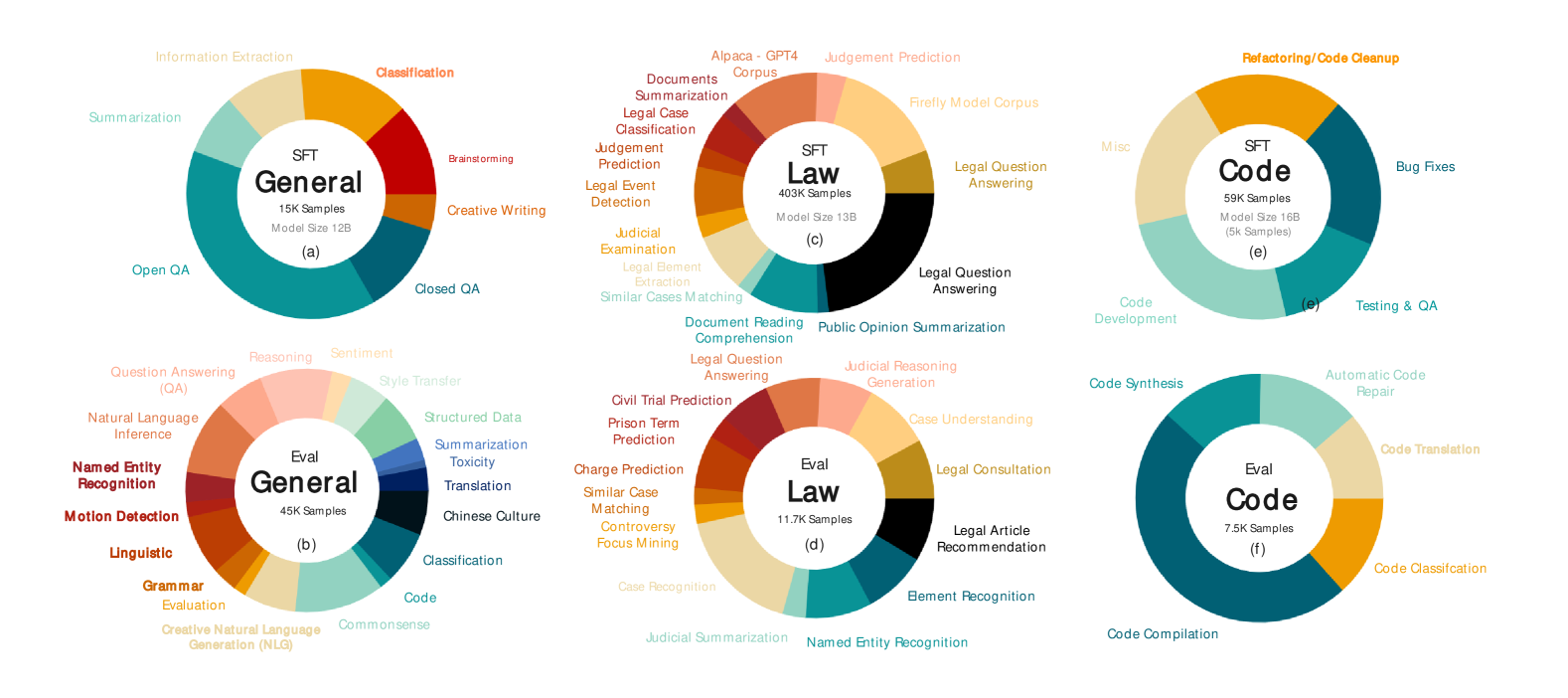
This survey provides a comprehensive taxonomy of the bidirectional relationship between data management and LLMs, defining the 'IaaS' (Inclusiveness, Abundance, Articulation, Sanitization) criteria for LLM data.
Core Problem
The integration of LLMs and data management is fragmented; LLMs require massive, high-quality data handling that challenges traditional systems, while traditional data tasks (cleaning, integration) remain manual and brittle.
Why it matters:
- Scalable development of LLMs depends on handling petabytes of multi-modal data efficiently, which current ad-hoc pipelines struggle to manage
- Traditional data manipulation relies on rigid rules that fail on complex or noisy data, whereas LLMs offer semantic flexibility but lack systematic integration
- Performance of RAG systems degrades significantly (e.g., up to 12%) as document volume increases, requiring specialized data serving techniques
Concrete Example:
In RAG, relying solely on vector similarity for 100,000-page datasets causes up to 12% accuracy degradation compared to smaller sets. Conversely, standardizing date formats like 'Fri Jan 1st' vs '1996.07.10' traditionally requires complex regex scripts, whereas LLMs can resolve these semantic inconsistencies automatically.
Key Novelty
Bidirectional Data×LLM Taxonomy & IaaS Framework
- Proposes 'IaaS' (Inclusiveness, Abundance, Articulation, Sanitization) as a principled framework to evaluate dataset quality across the LLM lifecycle
- Systematically categorizes DATA4LLM (processing, storage, serving for models) and LLM4DATA (using models for cleaning, integration, system tuning), unlike prior surveys focusing only on pre-training
Architecture
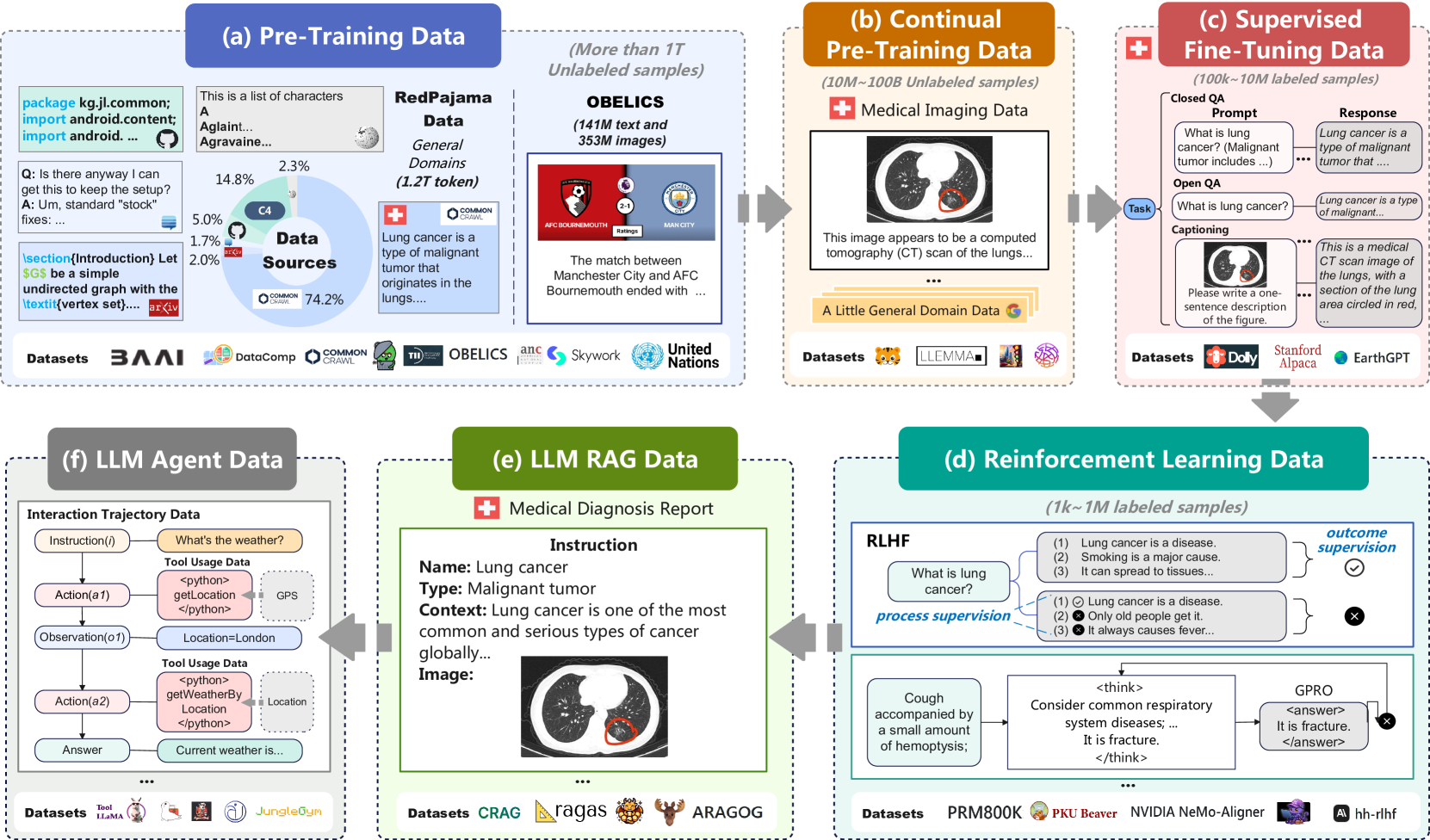
The bidirectional framework of Data×LLM. The left side shows DATA4LLM (Processing, Storage, Serving feeding into LLM lifecycle). The right side shows LLM4DATA (LLM enabling Manipulation, Analysis, Optimization).
Evaluation Highlights
- Highlights that RAG accuracy drops by up to 12% when scaling from 10,000 to 100,000 pages without advanced data serving techniques (Source: EyeLevel.ai)
- Notes that deep learning-based system tuning (e.g., RL/BO) requires >20 hours of workload replays for a single TPC-H workload, which LLM-based tuning can accelerate via context
- References DeepSeek-R1's 671B parameters and Qwen2.5-VL's ~4TB tokens as benchmarks for the scale of data storage and processing required
Breakthrough Assessment
9/10
A foundational survey that defines the scope of a new interdisciplinary field. It unifies scattered techniques into a coherent taxonomy, essential for future research in both database and AI communities.