📝 Paper Summary
LLM-based Ranking
Efficient LLM Inference
Semantic Search
MixLM accelerates LLM-based ranking by compressing long item descriptions into compact embeddings that are cached and mixed with query text, reducing inference costs while maintaining relevance.
Core Problem
Cross-encoder LLM rankers require processing long prompts containing both user queries and full item descriptions, leading to high computational costs and latency due to quadratic attention and prefill bottlenecks.
Why it matters:
- Industrial search systems have strict latency and throughput constraints that often prevent the deployment of powerful full-text LLM rankers.
- Existing solutions either sacrifice semantic depth by using smaller models or lose information by truncating inputs.
- High prefill costs limit the number of candidates that can be reranked in real-time.
Concrete Example:
A standard ranker prompt might contain thousands of tokens for a job description. For every query, the LLM must re-process these tokens, causing massive redundant computation. MixLM replaces the 2000+ token description with a single embedding token, drastically shortening the input.
Key Novelty
Text-Embedding Mix-Interaction
- Decouples the ranker's input into dynamic text (query) and static embeddings (items).
- Compresses item text into a few learned embedding tokens offline using an encoder LLM, then stores them in a cache.
- At inference, the ranker LLM processes a mixed prompt containing the natural language query and the retrieved item embeddings, bypassing the need to process the full item text.
Architecture
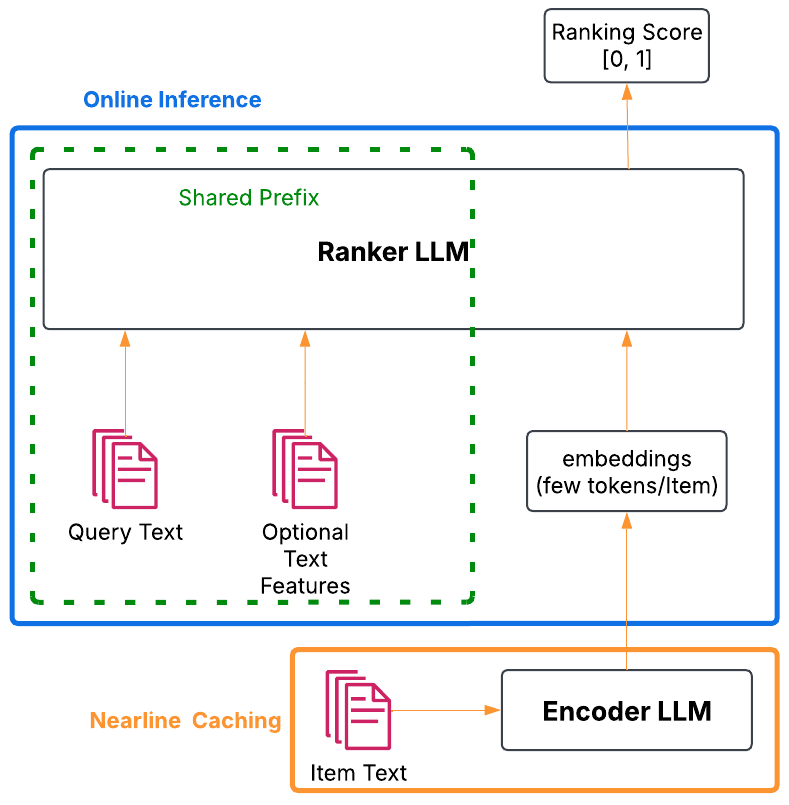
Overview of the MixLM architecture showing the split between offline encoding and online ranking.
Evaluation Highlights
- Improves serving throughput by 75.9× compared to a full-text LLM ranker baseline under a fixed latency budget.
- Achieves 10.0× higher throughput compared to a summarized-text LLM ranking baseline.
- Deployment in LinkedIn's Job Search resulted in a +0.47% increase in Daily Active Users (DAU) in online A/B testing.
Breakthrough Assessment
8/10
Significant practical breakthrough for industrial LLM deployment. It successfully bridges the gap between the semantic power of cross-encoders and the efficiency of representation-based methods, proven by large-scale production gains.