📝 Paper Summary
Collaborative Filtering (CF)
Knowledge Distillation from LLMs
Recommender Systems
LLM-KT improves collaborative filtering models by training them to reconstruct LLM-generated user profile embeddings within their internal layers, rather than using these features as direct inputs.
Core Problem
Existing methods for transferring knowledge from LLMs to recommender systems typically require models that accept textual features as input, excluding many traditional Collaborative Filtering (CF) architectures.
Why it matters:
- Traditional CF models (like Matrix Factorization) often struggle to capture nuanced user preferences from interactions alone but cannot natively process the rich reasoning chains generated by LLMs.
- Current LLM enhancement methods (e.g., KAR, LLM-CF) are limited to context-aware models that handle input features, leaving a gap for improving simpler, widely-used CF baselines.
- Direct use of LLMs for inference is prohibitively expensive, necessitating efficient knowledge transfer methods.
Concrete Example:
A Matrix Factorization model (NeuMF) cannot take an LLM-generated text summary like 'User loves 90s sci-fi' as input because it only accepts user/item IDs. Current methods would fail or require architecture changes, whereas LLM-KT injects this knowledge by forcing the model's internal embeddings to match the text summary's embedding.
Key Novelty
Internal Feature Reconstruction as Knowledge Transfer
- Instead of feeding LLM features as input, LLM-KT treats the LLM-generated user profile embedding as a target for the CF model to reconstruct inside its hidden layers.
- This approach acts as a 'side quest' (pretext task) during training: the model learns to organize its internal user representations to align with the semantic richness of LLM profiles without changing its inference architecture.
Architecture
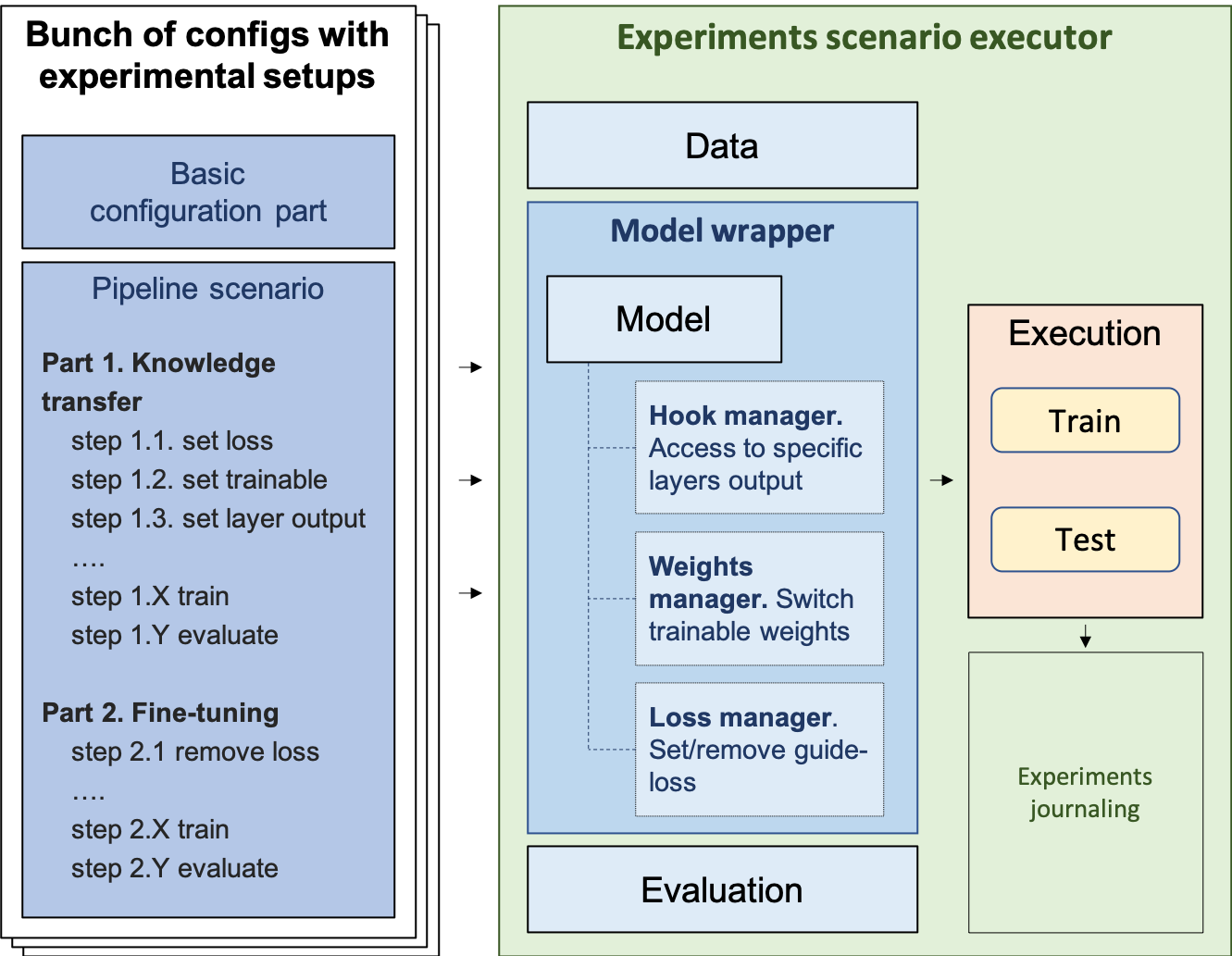
The LLM-KT framework architecture integrated with RecBole, showing the pipeline from dataset to model training.
Evaluation Highlights
- +21% improvement in NDCG@10 on Amazon CD and Vinyl dataset for the SimpleX baseline compared to the base model.
- Consistent improvements across three diverse baselines (NeuMF, SimpleX, MultVAE) on both MovieLens and Amazon datasets.
- Achieves competitive performance with state-of-the-art KAR on context-aware models (DeepFM, DCN) while being applicable to a broader range of architectures.
Breakthrough Assessment
6/10
A clever, versatile engineering framework that extends LLM benefits to legacy CF models. While the core idea (distillation) is known, the specific application to internal layer reconstruction for model-agnosticism is valuable.