📊 Experiments & Results
Evaluation Setup
Fine-tuning base models on diverse instruction datasets and evaluating on standard NLP benchmarks
Benchmarks:
- MMLU (5-shot Knowledge & Reasoning (Multiple Choice))
- MTBench (Multi-turn Conversational Evaluation (LLM-as-a-judge))
- Open LLM Leaderboard v2 (Diverse (MMLU-Pro, GPQA, MuSR, MATH, IFEval, BBH))
Metrics:
- Score (Accuracy or Rating)
- Loss
- Gradient Norm
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
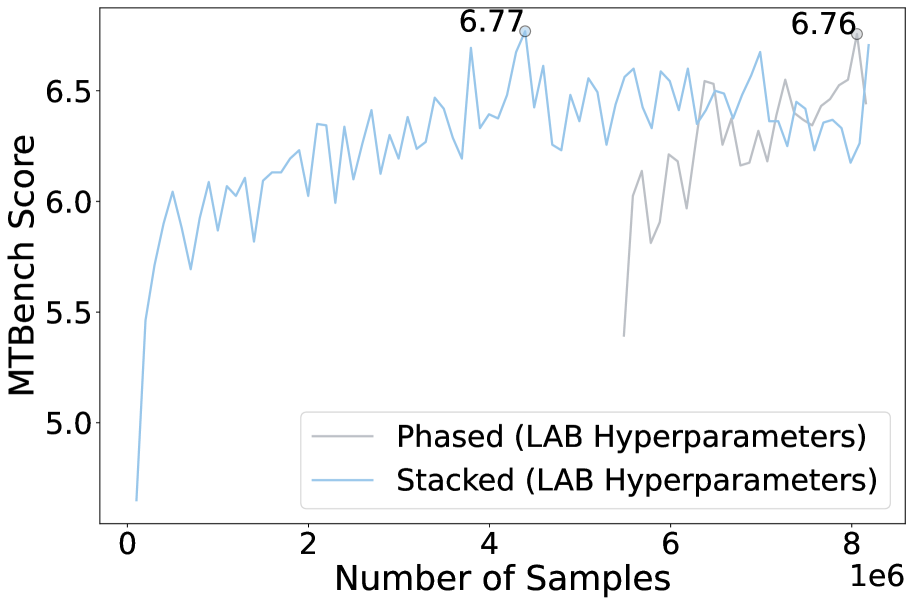
| Comparison of training strategies shows that the simpler Stacked approach matches the performance of the more complex Phased approach. | ||||
| MTBench | Score | 7.63 | 7.70 | +0.07 |
| MMLU | Score | 0.57 | 0.59 | +0.02 |
| Hyperparameter optimization reveals that the proposed TULU++ configuration (large batch, constant LR) outperforms the standard TULU recipe. | ||||
| MTBench | Score | 6.36 | 7.01 | +0.65 |
| MMLU | Score | 0.55 | 0.59 | +0.04 |
| GSM8K | Score | 0.41 | 0.49 | +0.08 |
Experiment Figures
Heatmaps showing MT-Bench scores for Granite 3B and Mistral 7B across different batch sizes and learning rates.
Plots of Gradient Norm and Training Loss over time for different learning rates.
Main Takeaways
- Larger batch sizes combined with lower learning rates consistently lead to better generalization and downstream performance
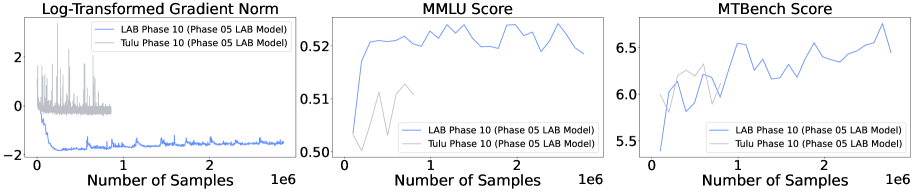
- Stacked training is as effective as Phased training but significantly simpler and more sample efficient
- Early training dynamics (lower gradient norms, higher loss) are strong indicators of better final performance, enabling early stopping of sub-optimal runs
- Simplifications like constant learning rates and removing warmup steps do not compromise model quality