📝 Paper Summary
E-commerce Search
LLM-based Ranking
The paper introduces SUPERB, a dataset and four-level relevance schema for 'best X' queries, and demonstrates that LLM-based listwise ranking significantly outperforms traditional retrieval for identifying the best products.
Core Problem
Traditional retrieval systems struggle with 'implicit superlative queries' (e.g., 'best shoes for marathons') because they rely on explicit keyword matching rather than inferring complex, subjective attributes like durability or safety.
Why it matters:
- Users frequently search for the 'best' products using vague terms, leading to query-product mismatches in standard systems
- Existing relevance labels (like ESCI) capture objective relevance (Exact/Substitute) but fail to capture the subjective quality or superiority required for superlative queries
Concrete Example:
For the query 'best toy for a 3 year old girl', a standard system might return any toy matching the keywords. However, a superlative system must infer implicit attributes like 'ASTM F963 safety standards', 'non-toxic materials', and 'engaging colors' to recommend the actual best options.
Key Novelty
SUPERB (Superlatives with Best relevance annotations)
- Proposes a four-point relevance schema (Overall Best, Almost Best, Relevant But Not Best, Not Relevant) specifically designed to distinguish top-tier products from merely relevant ones
- Introduces 'Deliberated Prompting' for ranking: forcing the LLM to first generate implicit product attributes (reasoning) before assigning a relevance label to reduce bias and improve accuracy
Architecture

The Deliberated Prompting workflow for generating relevance annotations
Evaluation Highlights
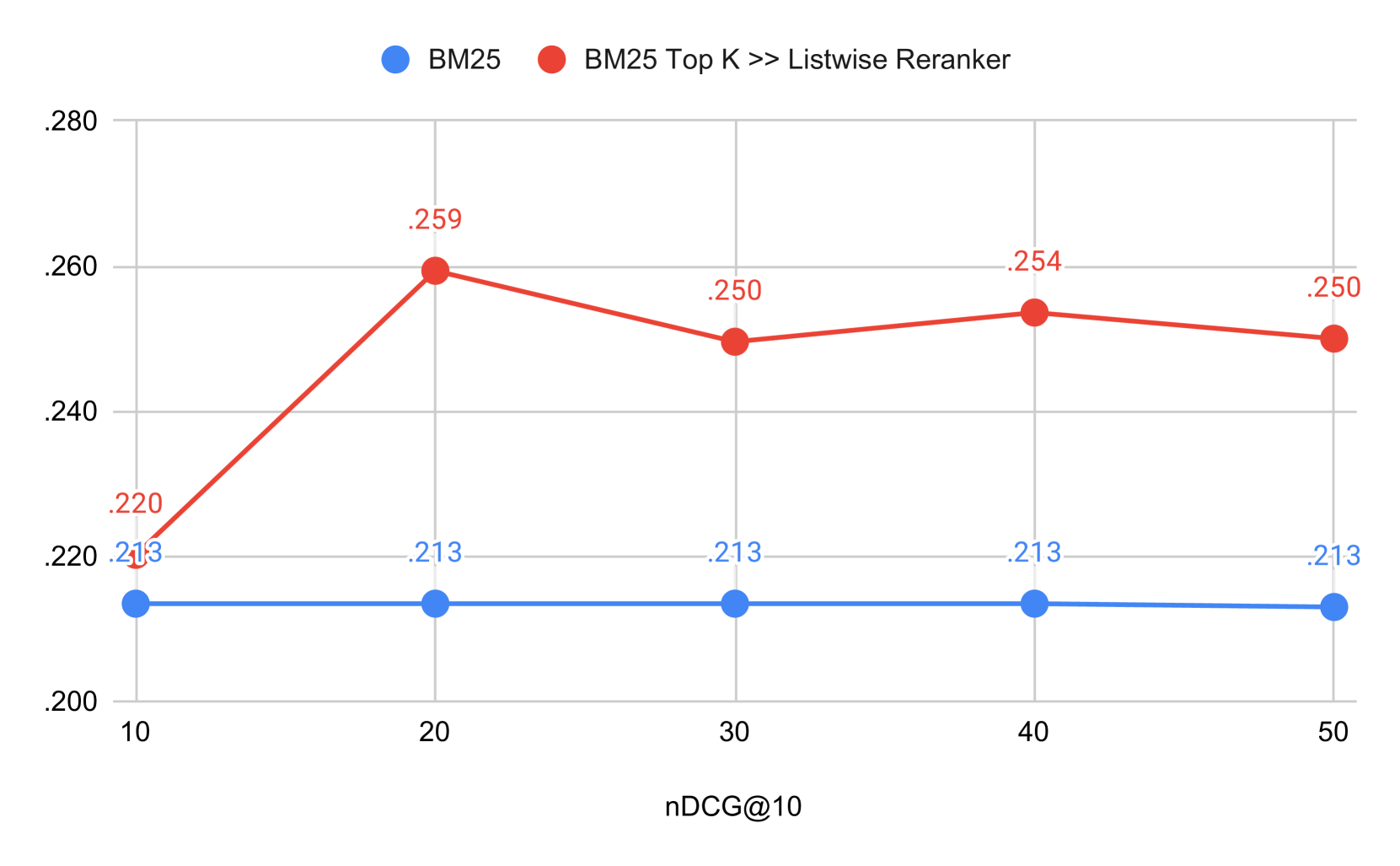
- Listwise re-ranking achieves 0.529 nDCG@10, significantly outperforming the BM25 baseline (0.380) on the SUPERB dataset
- Sliding-window listwise ranking on top-100 items yields 0.449 nDCG@10 compared to 0.347 for BM25, showing robustness in larger contexts
- Listwise approaches consistently outperform pointwise and pairwise LLM ranking methods for superlative queries
Breakthrough Assessment
7/10
Establishes a necessary formalization for a common but under-studied query type ('implicit superlatives') and provides a dataset/schema (SUPERB) that enables future work, though the modeling techniques (Listwise/CoT) are existing methods applied to this new domain.