📝 Paper Summary
LLM for Recommendation (LLM4Rec)
Incremental Learning
Parameter-Efficient Fine-Tuning (PEFT)
Common incremental learning strategies fail to improve LLM4Rec performance, so the authors propose using separate LoRA modules to independently capture long-term and short-term user preferences.
Core Problem
Standard incremental learning methods (full retraining and fine-tuning) surprisingly fail to improve the performance of LoRA-based LLM recommender systems compared to static models.
Why it matters:
- Recommender systems must adapt to evolving user preferences and new items to remain effective in real-world deployment
- LLMs have unique characteristics (massive parameters, high tuning costs) that make traditional incremental learning assumptions potentially invalid
- A single LoRA adapter struggles to balance the conflicting goals of retaining long-term patterns while adapting to rapid short-term shifts
Concrete Example:
In a movie recommendation scenario, a user might have a long-standing preference for Sci-Fi (long-term) but suddenly binge Rom-Coms over the weekend (short-term). A standard LoRA trained on all history ignores the recent shift due to data imbalance, while fine-tuning only on recent data forgets the Sci-Fi preference. Consequently, standard updates don't improve over a static model.
Key Novelty
Long- and Short-term Adaptation-aware Tuning (LSAT)
- Decomposes the single adaptation module into two separate LoRA modules: one fixed/slow-updating for long-term preferences and one frequently retrained for short-term preferences
- Dynamically merges the outputs of these two modules during inference (via ensemble or parameter fusion) to balance stability and plasticity without catastrophic forgetting
Architecture
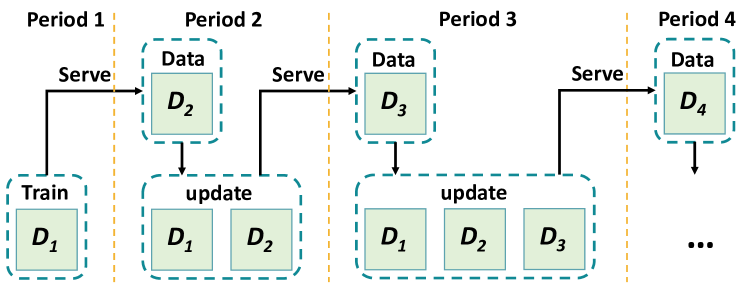
Conceptual workflow of LSAT (described in text, not explicitly drawn as a single system diagram in the PDF snippet provided, but described in Section 5).
Evaluation Highlights
- LSAT outperforms both full retraining and fine-tuning strategies across MovieLens-1M and Amazon-Book datasets
- Standard fine-tuning leads to performance degradation on ML-1M due to catastrophic forgetting, while LSAT prevents this
- TALLRec (the base LLM4Rec model) shows strong zero-shot generalization to cold-start items even without incremental updates, unlike traditional collaborative filtering models which fail completely
Breakthrough Assessment
7/10
Provides a crucial negative result (standard incremental learning fails for LLM4Rec) and a logical, effective architectural solution (LSAT). The finding that LLMs generalize well enough to make frequent retraining less critical is also significant.