📝 Paper Summary
Domain-specific LLM Reasoning
Chain-of-Thought (CoT) optimization
Explainable AI (XAI)
Domaino1s enhances high-stakes domain reasoning by fine-tuning LLMs on structured CoT data and employing a perplexity-guided tree search to autonomously expand and select optimal reasoning paths.
Core Problem
Standard LLMs in high-stakes domains (finance/law) often generate brief, unexplainable answers or follow flawed single-pass reasoning chains that accumulate errors.
Why it matters:
- Users in high-stakes fields require explainability to trust decisions; black-box answers are insufficient
- Single-pass CoT lacks self-correction; early errors propagate through the entire chain, leading to legal or financial risks
- Existing o1-type reasoning models have not yet been effectively adapted or explored for specific high-stakes domain constraints
Concrete Example:
In stock prediction, a standard CoT model might misinterpret a 'strategic initiative' early in the reasoning chain. Because it cannot backtrack, it builds the rest of its financial analysis on this initial error, resulting in an incorrect 'positive' price prediction.
Key Novelty
Domaino1s (Domain-specific o1-style reasoning)
- Fine-tunes models on domain-specific CoT data (Finance/Legal) where structured reasoning steps are learned but special tokens are removed, forcing the model to autonomously organize its thinking process
- Introduces 'Selective Tree Exploration', a search strategy that uses token perplexity as a proxy for value, expanding the reasoning tree only when model uncertainty (perplexity) is high
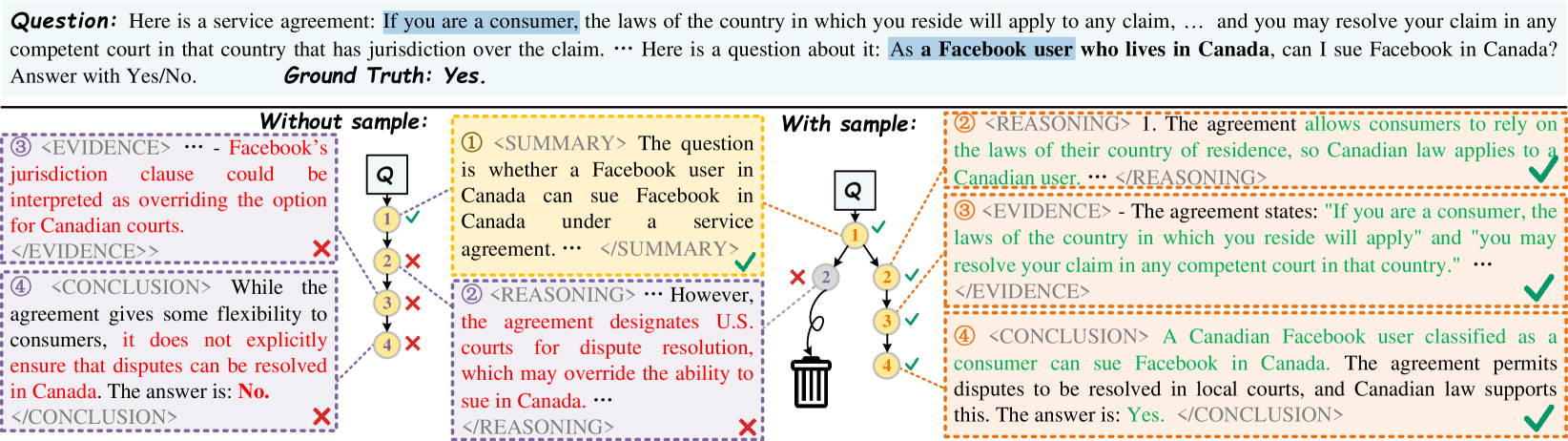
Architecture

Comparison between Standard CoT and Domaino1s inference processes. It illustrates how Standard CoT propagates errors linearly, while Domaino1s uses a tree search to explore and correct paths.
Evaluation Highlights
- Achieves 57.29% accuracy on Stock Investment Recommendation, outperforming standard CoT (53.12%) and o1-like baselines
- Reaches 78.33% average accuracy on Legal Reasoning QA, surpassing Domain-CoT (77.09%) and Lawma-8B (44.46%)
- Proposed Selective Tree Exploration balances performance and cost, achieving higher accuracy than Best-of-N while using fewer tokens
Breakthrough Assessment
7/10
Successfully adapts o1-style reasoning to specific domains with a practical, perplexity-based search method. While the architectural innovation is moderate, the application to high-stakes domains and the new explainability metric are valuable.