📝 Paper Summary
User Simulation for Recommender Systems
LLM Alignment
UserMirrorer aligns user simulators with human preferences by distilling high-quality training data from massive, noisy user feedback using uncertainty estimation and LLM-generated decision rationales.
Core Problem
Existing LLM-based user simulators struggle with task alignment because raw user feedback is ambiguous (lacks reasoning) and noisy, while powerful LLMs are too computationally expensive for large-scale simulation.
Why it matters:
- Online testing (A/B testing) is slow (weeks/months) and raises privacy concerns, creating a need for accurate offline simulators
- Raw behavioral logs (e.g., clicks) do not explain *why* a user acted, preventing models from learning the underlying decision process
- Directly fine-tuning on massive, noisy feedback data is inefficient and can degrade model performance due to low-quality samples
Concrete Example:
A raw log shows a user watched 'Crimson Tide', but doesn't explain if they chose it for the actor (Denzel Washington) or the genre (Thriller). A standard simulator might guess randomly. UserMirrorer generates the specific rationale (e.g., 'User prefers suspenseful military movies') to teach the simulator the correct reasoning path.
Key Novelty
UserMirrorer Framework (Uncertainty-based Data Distillation)
- Transforms raw user feedback into simulation scenes and uses a powerful 'Teacher' LLM to generate explicit decision-making processes (rationales) based on the EKB consumer behavior model
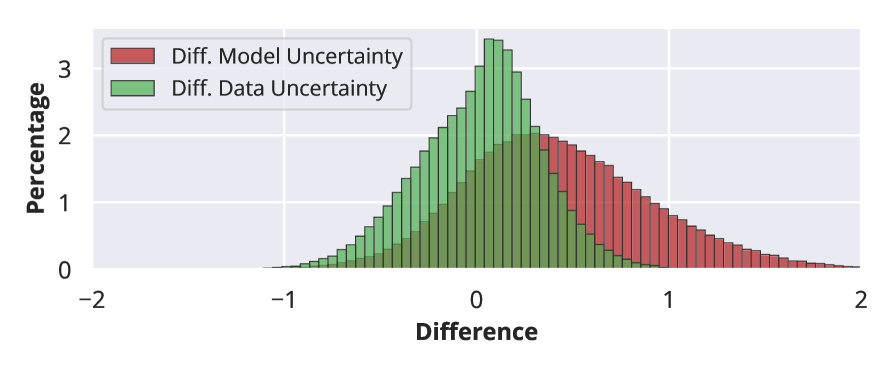
- Distills training data by selecting 'challenging' samples where the epistemic uncertainty gap between the Teacher (strong LLM) and Student (weak LLM) is large, ensuring the Student learns from cases it finds difficult
- Filters noise by verifying that the Teacher's generated reasoning leads to the actual ground-truth user action before adding it to the training set
Architecture
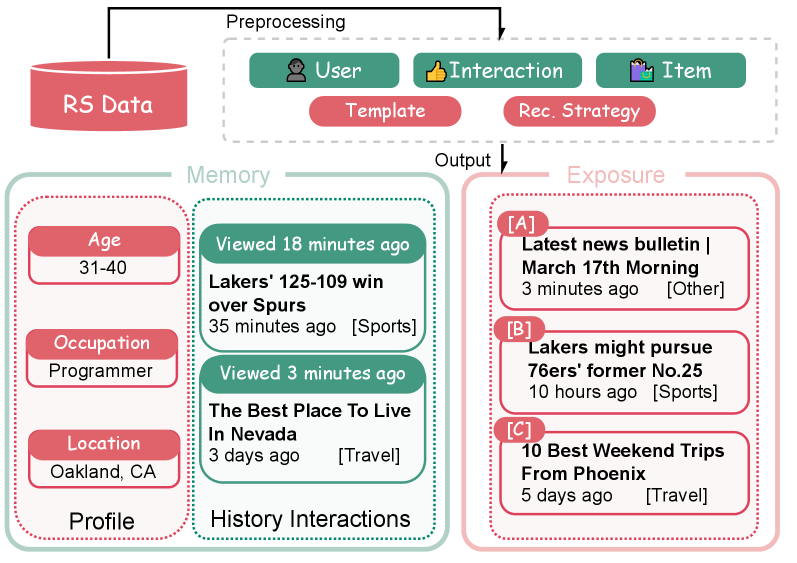
The construction of a 'User Simulation Scene' from raw data. Shows how User Profile and Interaction History are converted into a 'Memory' text block, and how items are formed into an 'Exposure' list.
Evaluation Highlights
- Significant qualitative improvement in alignment with human preferences compared to non-fine-tuned baselines (numeric results not included in provided text snippet)
- Stronger base models (e.g., Qwen-2.5-32B) inherently align better with user behavior than weaker ones (Llama-3.2-3B) before fine-tuning
- Successfully distills data from 8 diverse domains (movies, books, news, etc.) into a unified format for simulator training
Breakthrough Assessment
7/10
Addresses a critical bottleneck in Recommender Systems (data ambiguity/noise) with a logically sound uncertainty-based distillation method. However, the score is tentative as quantitative performance metrics were not available in the provided text.