📝 Paper Summary
User Modeling
Content-Based Recommendation
EmbSum improves content recommendations by encoding users and items into multiple embedding vectors and supervising the user encoder with an auxiliary task where it must summarize user interests like an LLM.
Core Problem
Existing content-based recommenders either truncate user history to fit memory limits (losing long-term interests) or encode items independently (losing interaction context between items).
Why it matters:
- Truncating history to ~1K tokens prevents systems from understanding a user's comprehensive long-term preferences
- Online calculation strategies (concatenating user and candidate items) prevent efficient offline pre-computation, making inference too slow for real-world scale
- Independent encoding fails to capture how a user's interest in one item (e.g., 'NBA') relates to another (e.g., 'Sneakers') within their history
Concrete Example:
A user has browsed 60 news items, totaling 7,440 tokens. Standard BERT-based models truncate this to 512 or 1024 tokens, ignoring early history. EmbSum encodes all 60 items in chunks and fuses them by learning to generate a text summary (e.g., 'Interests: Sci-Fi and Cooking') supervised by an LLM.
Key Novelty
EmbSum (Embedding and Summarization)
- User Poly-Embedding (UPE): Instead of a single vector, users are represented by multiple vectors derived via poly-attention to capture diverse interest facets
- LLM-Supervised Summarization: Uses a large model (Mixtral) to generate 'gold' summaries of user history, then trains a smaller model's decoder to reproduce these summaries as an auxiliary task to force better representation learning
Architecture
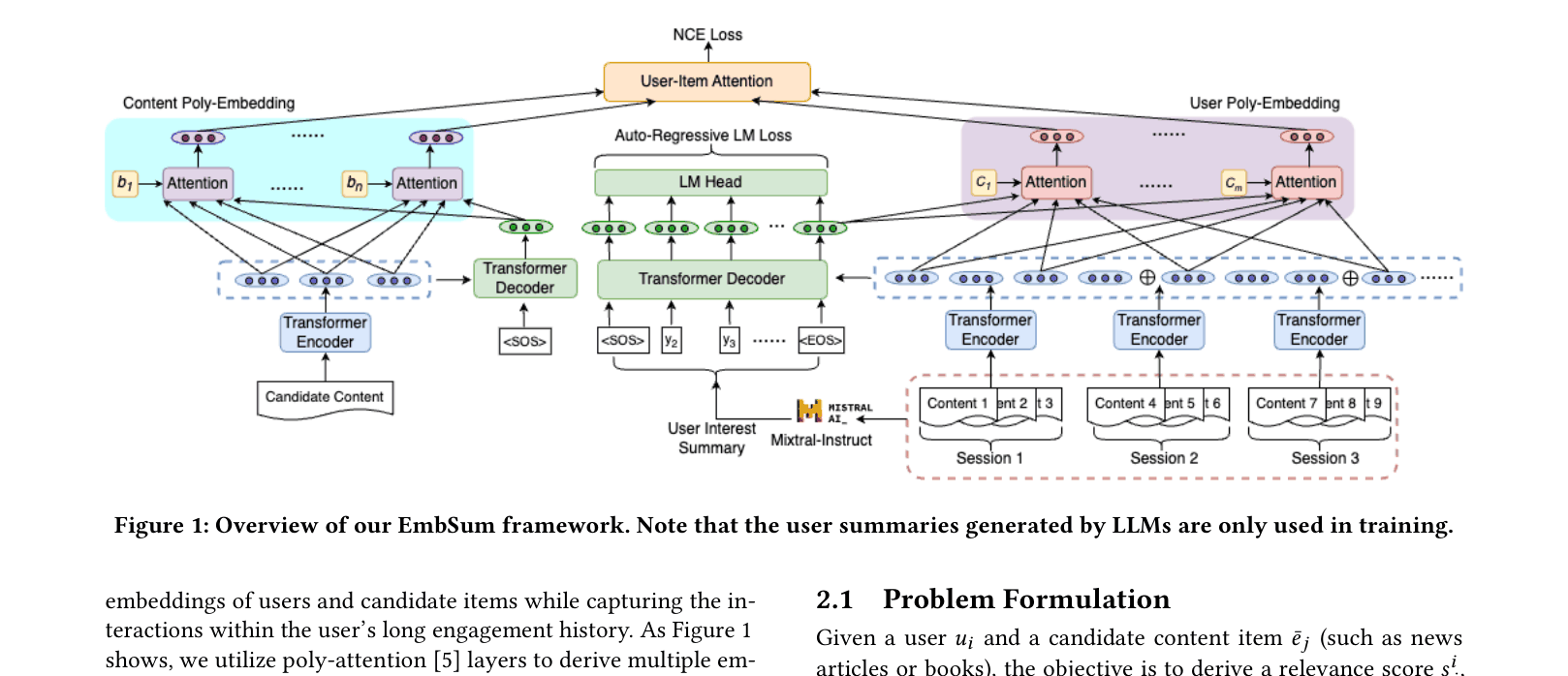
The dual-branch architecture of EmbSum. Top branch: User history encoding via sessions, leading to UPE (Poly-Embedding) and a Summarization Decoder. Bottom branch: Candidate content encoding leading to CPE. Right side: Interaction via attention matching.
Evaluation Highlights
- Outperforms SoTA UNBERT by +0.22 AUC on MIND dataset while using ~50% fewer parameters (61M vs 125M)
- Achieves highest ranking accuracy (MRR 38.58) on MIND, surpassing MINER (38.10) and UniTRec (37.62)
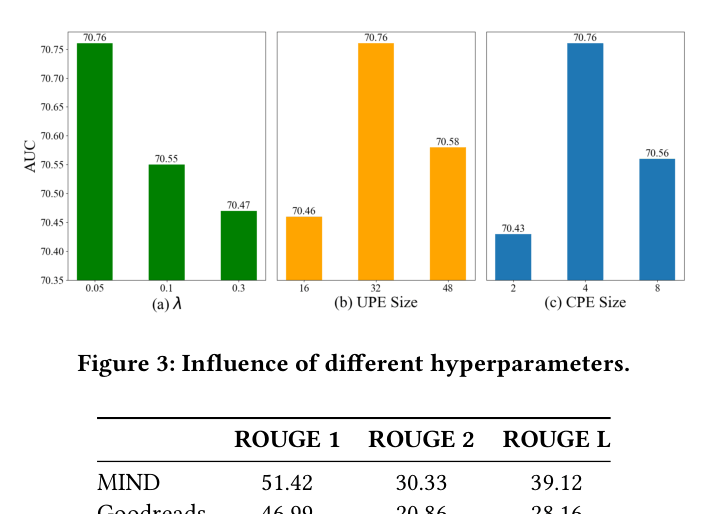
- Generating multiple embeddings for items (CPE) improves AUC by +3.78 on MIND compared to single-vector item representation
Breakthrough Assessment
7/10
Effective combination of parameter-efficient architecture (T5-small) with LLM supervision to beat heavier baselines. Incremental but consistent gains; strong practical value due to offline inference capability.