📝 Paper Summary
Industrial Recommendation Systems
CTR Prediction / Ranking
RankMixer scales industrial ranking models to one billion parameters by replacing inefficient CPU-era modules with a hardware-aware architecture using multi-head token mixing and per-token feed-forward networks.
Core Problem
Traditional ranking models use handcrafted feature-crossing modules inherited from the CPU era, which suffer from extremely low Model Flops Utilization (MFU) on modern GPUs and fail to scale effectively.
Why it matters:
- Industrial recommenders must adhere to strict latency bounds and high QPS, making inefficient scaling viable only if computational cost is managed
- Existing scaling attempts often yield modest or negative gains because they just widen layers without addressing the memory-bound nature of heterogeneous feature interactions
- Standard Transformers (self-attention) are suboptimal for recommendation due to the difficulty of computing inner products between heterogeneous feature spaces (e.g., user vs. item IDs)
Concrete Example:
Previous baseline models at ByteDance achieved only ~4.5% MFU on GPUs because their operators were memory-bound. Scaling them up linearly increased latency beyond acceptable limits, preventing the realization of scaling laws seen in NLP.
Key Novelty
Hardware-Aware RankMixer Architecture
- Replaces quadratic self-attention with a parameter-free Multi-Head Token Mixing module to handle cross-token interactions without expensive inner-product calculations
- Uses Per-Token Feed-Forward Networks (FFNs) to isolate parameters for different feature subspaces, preventing high-frequency features from dominating the learning process
- Extends to a Sparse Mixture-of-Experts (MoE) variant with a dynamic routing strategy to scale capacity to 1 billion parameters while keeping inference cost constant
Architecture
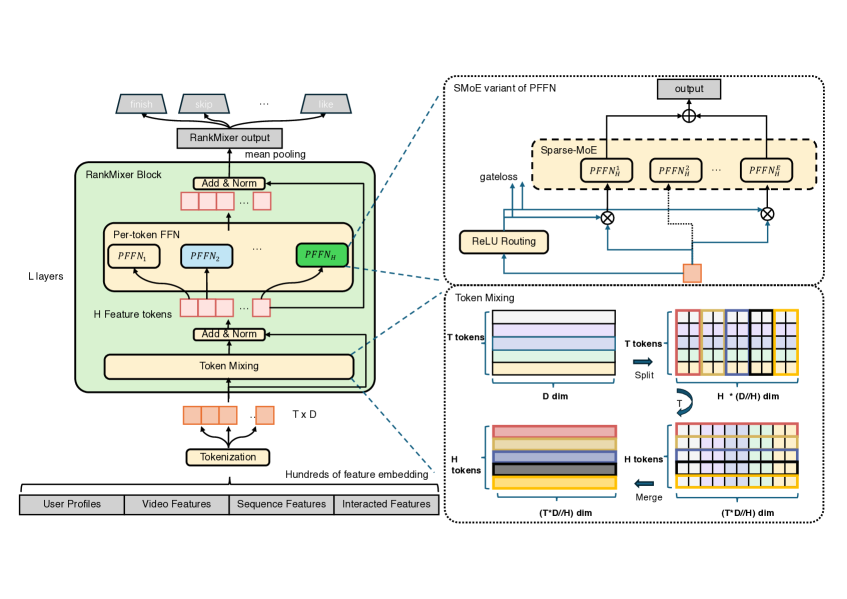
The RankMixer architecture block processing T tokens
Evaluation Highlights
- Boosted Model Flops Utilization (MFU) from 4.5% to 45% by replacing handcrafted modules with the RankMixer architecture
- Scaled online ranking model parameters by 70x (up to 1 billion) without increasing inference latency or serving cost
- Achieved +0.3% user active days and +1.08% total in-app usage duration in full-traffic A/B testing on Douyin Feed Recommendation
Breakthrough Assessment
8/10
Significant industrial breakthrough proving scaling laws in recommendation systems. Successfully deployed a 1B parameter model in a high-QPS production environment by radically optimizing hardware utilization (MFU).