📝 Paper Summary
Personalized Text Generation
Recommender Systems (RS)
Review-LLM customizes large language models to write personalized product reviews by aggregating user history and ratings into prompts, then fine-tuning to overcome the models' tendency to be overly polite.
Core Problem
General-purpose LLMs fail to generate personalized product reviews because they lack knowledge of specific user styles and tend to be overly "polite," struggling to write negative reviews even when users are dissatisfied.
Why it matters:
- Reviews provide crucial explanations for recommendations and help other users understand products, but many users only leave ratings without text.
- Existing LLMs are pre-trained on general corpora and miss individual writing habits, leading to generic outputs.
- The "politeness" of LLMs prevents them from accurately reflecting user dissatisfaction, reducing the reliability of generated feedback.
Concrete Example:
If a user rates an item 1 star (dissatisfied), a standard LLM like Llama-3 might still generate a polite or neutral review. Review-LLM uses the rating and history to correctly generate a negative review reflecting the user's specific complaints.
Key Novelty
Review-LLM (User History & Rating Aggregation + SFT)
- Constructs a rich prompt containing the user's historical purchases (titles and reviews) and the target item's rating to teach the model the user's specific writing style and sentiment.
- Explicitly incorporates the numerical rating into the prompt as a signal of satisfaction, forcing the model to align the generated text's sentiment (positive/negative) with the user's actual score.
- Fine-tunes the LLM using Parameter-Efficient Fine-Tuning (PEFT) on this structured data to adapt general language capabilities to the personalized review generation task.
Architecture

The prompt construction and fine-tuning pipeline.
Evaluation Highlights
- Review-LLM (based on Llama-3-8b) outperforms significantly larger closed-source models (GPT-3.5-Turbo and GPT-4o) on ROUGE and BERTScore metrics.
- On a 'hard' test set of negative reviews, the fine-tuned model maintains performance while the base Llama-3-8b collapses (BERTScore drops to 26.96), proving the method mitigates the 'politeness' bias.
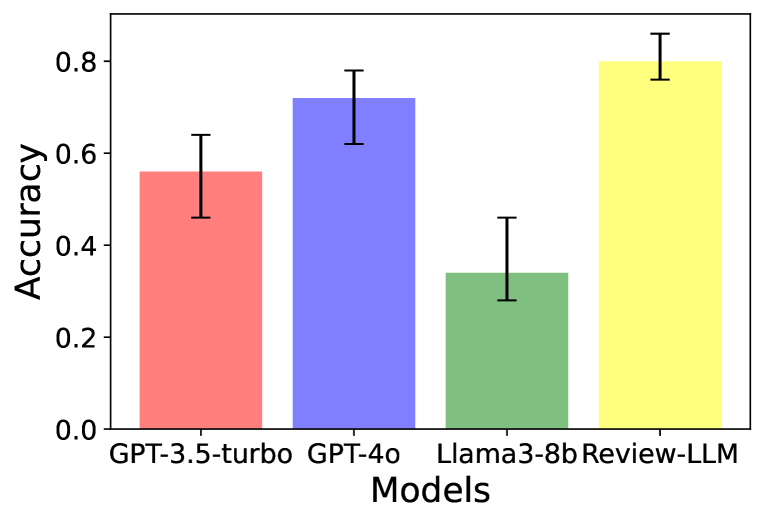
- Human evaluation shows generated reviews are semantically consistent with reference reviews 87% of the time, compared to 58% for GPT-4o.
Breakthrough Assessment
4/10
Effective application of SFT to a specific domain problem (review generation), showing that smaller fine-tuned models can beat larger general ones. Primarily an engineering application rather than a fundamental architectural breakthrough.