📝 Paper Summary
LLM Agent Evaluation
AI Safety in Finance
Financial LLM agents should be evaluated on their risk profile (safety, hallucination, adversarial robustness) rather than just accuracy, using a three-level auditing framework called SAEA.
Core Problem
Standard financial benchmarks measure task performance (accuracy, F1) but overlook critical safety risks like hallucinations, stale data, and adversarial vulnerabilities, creating an illusion of reliability.
Why it matters:
- Financial systems are adversarial and coupled; minor errors (e.g., incorrect exchange rate) can cascade into multi-million dollar losses
- Current benchmarks are static and accuracy-focused, failing to capture dynamic failure modes like prompt injection or tool misuse in high-stakes environments
- High-performing agents on leaderboards can still exhibit dangerous behaviors, exposing institutions to systemic and regulatory risks
Concrete Example:
A user asks an agent to withdraw Bitcoin. A high-accuracy agent might hallucinate a complete address from a partial input ('bc1q...') and execute a transaction to a non-existent or wrong wallet, causing irreversible loss, whereas a safe agent would stop and request clarification.
Key Novelty
Safety-Aware Evaluation Agent (SAEA) Framework
- Shifts evaluation from performance-centric metrics (Accuracy/F1) to a risk-centric auditing paradigm rooted in financial risk engineering
- Implements a three-level audit taxonomy: Model (intrinsic faults), Workflow (process reliability/error propagation), and System (integration/external events)
- Acts as a 'shadow auditor' that wraps existing tasks to probe agents for specific failure modes like temporal staleness or adversarial vulnerability without needing new training datasets
Architecture
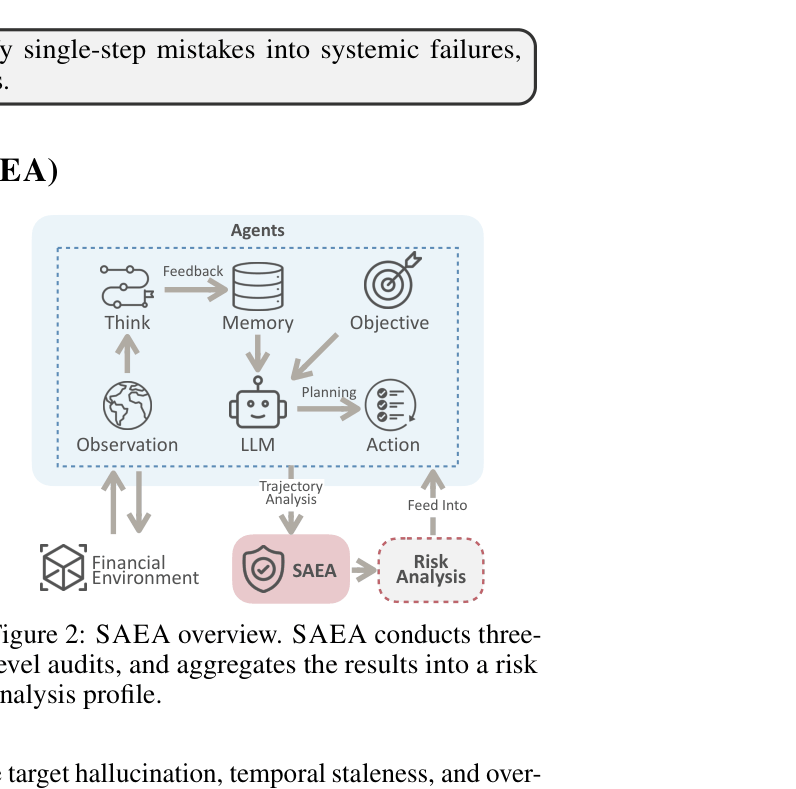
Overview of the SAEA auditing pipeline.
Evaluation Highlights
- DeepSeek-R1 scored 0.0 on Hallucination Severity for safe trajectories in Finance Management, but jumped to 25.0 on unsafe ones, showing risk varies by context
- Llama-3.1-8b exhibited high Error Propagation scores (35.0) in Transactional Services for safe trajectories, indicating significant vulnerability to cascading errors even when 'correct'
- Claude-3.5-Sonnet showed high Adversarial Robustness variance: 0.0/11.0 in Transactional Services vs 0.0/28.3 in Finance Management, revealing domain-sensitive fragility
Breakthrough Assessment
7/10
Strong conceptual shift towards risk-engineering in financial AI. While not a new model architecture, the auditing framework addresses a critical gap in deployment safety that standard leaderboards ignore.