📝 Paper Summary
LLM-based Recommender Systems (LLM-RS)
Fairness and Bias Mitigation
Machine Unlearning
FUDLR mitigates fairness issues in LLM-based recommender systems by efficiently identifying bias-inducing training samples via mask learning and removing their influence through a fast, retraining-free machine unlearning update.
Core Problem
LLM-based recommenders inherit biases (like popularity or attribute bias) from training data, but existing debiasing methods lack generality across bias types and require computationally prohibitive retraining.
Why it matters:
- LLMs trained on massive, unaligned datasets often perpetuate stereotypes or over-recommend popular items, harming user experience and niche item visibility
- Retraining or fine-tuning large models for every specific fairness constraint is operationally infeasible for dynamic, large-scale systems
- Existing solutions are often tailored to single bias types, failing to address the diverse or co-existing biases found in real-world applications
Concrete Example:
A recommender trained on historical data might over-recommend blockbuster movies (popularity bias) or systematically suggest lower-paying jobs to certain demographic groups (attribute bias). Current methods would require re-running the expensive fine-tuning process with re-weighted loss to fix this, whereas FUDLR updates the existing model directly.
Key Novelty
Fast Unified Debiasing for LLM-RS (FUDLR)
- Reformulates debiasing as a machine unlearning task: instead of retraining, it mathematically estimates how the model parameters would change if biased samples were removed
- Uses a learnable 'mask' to identify which specific training samples cause bias, optimizing this mask to balance fairness improvement, accuracy preservation, and sparsity
- Decouples bias identification from the unlearning mechanism, allowing the system to target different biases (popularity, gender, etc.) simply by swapping the fairness metric used in the mask objective
Architecture
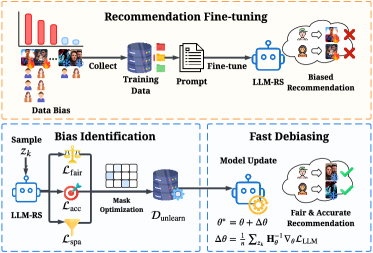
The overall FUDLR framework illustrating the two-stage process: Bias Identification via Mask Learning and Fast Debiasing via Unlearning.
Evaluation Highlights
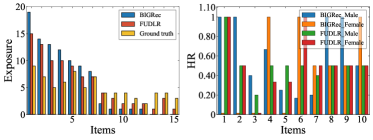
- Mitigates popularity bias while maintaining recommendation accuracy, outperforming retraining-based baselines in the fairness-accuracy trade-off
- Achieves comparable or better debiasing performance than full retraining methods but with significantly lower computational cost (orders of magnitude faster)
- Demonstrates generality by effectively reducing both item-side popularity bias and user-side attribute bias (e.g., gender discrimination) using the same framework
Breakthrough Assessment
8/10
Offers a highly practical solution to a critical problem (fairness) in a high-cost domain (LLMs) by successfully applying machine unlearning. The unification of different bias types under one framework is a significant methodological advance.