📝 Paper Summary
Reinforcement Learning for Recommender Systems (RL4Rec)
User Simulation
Synthetic Environments
SUBER is a modular reinforcement learning environment that uses Large Language Models to simulate human users, their preferences, and rating behaviors, enabling the training of recommender systems without expensive online human interaction.
Core Problem
Training RL-based recommender systems requires massive online data, but experimenting on real users risks them abandoning the platform due to poor initial recommendations, while offline data is static and biased.
Why it matters:
- Real-world data collection is expensive and risky because bad recommendations degrade user experience (exploration costs)
- Offline evaluation metrics often fail to correlate with real-world performance
- Existing simulators (like RecoGym or RecSim) rely on simpler mathematical models that lack the semantic understanding and behavioral complexity of human users
Concrete Example:
In a movie recommendation setting, a standard RL agent needs feedback to learn. If trained on real users, it might recommend random irrelevant movies to explore, causing users to quit. SUBER allows the agent to make these mistakes on a synthetic LLM-based user first, receiving realistic ratings (e.g., 1-10 stars) based on a generated persona.
Key Novelty
LLM-based User Simulation for RL Environments
- Replaces mathematical user models with Large Language Models (LLMs) that act as synthetic users, predicting how a specific persona would rate a given item based on history
- Introduces modular components to simulate specific human behaviors like 'Concept Drift' (evolving interests) and 'Fleeting Interests' (spontaneous decisions) via reward perturbation and shaping
Architecture
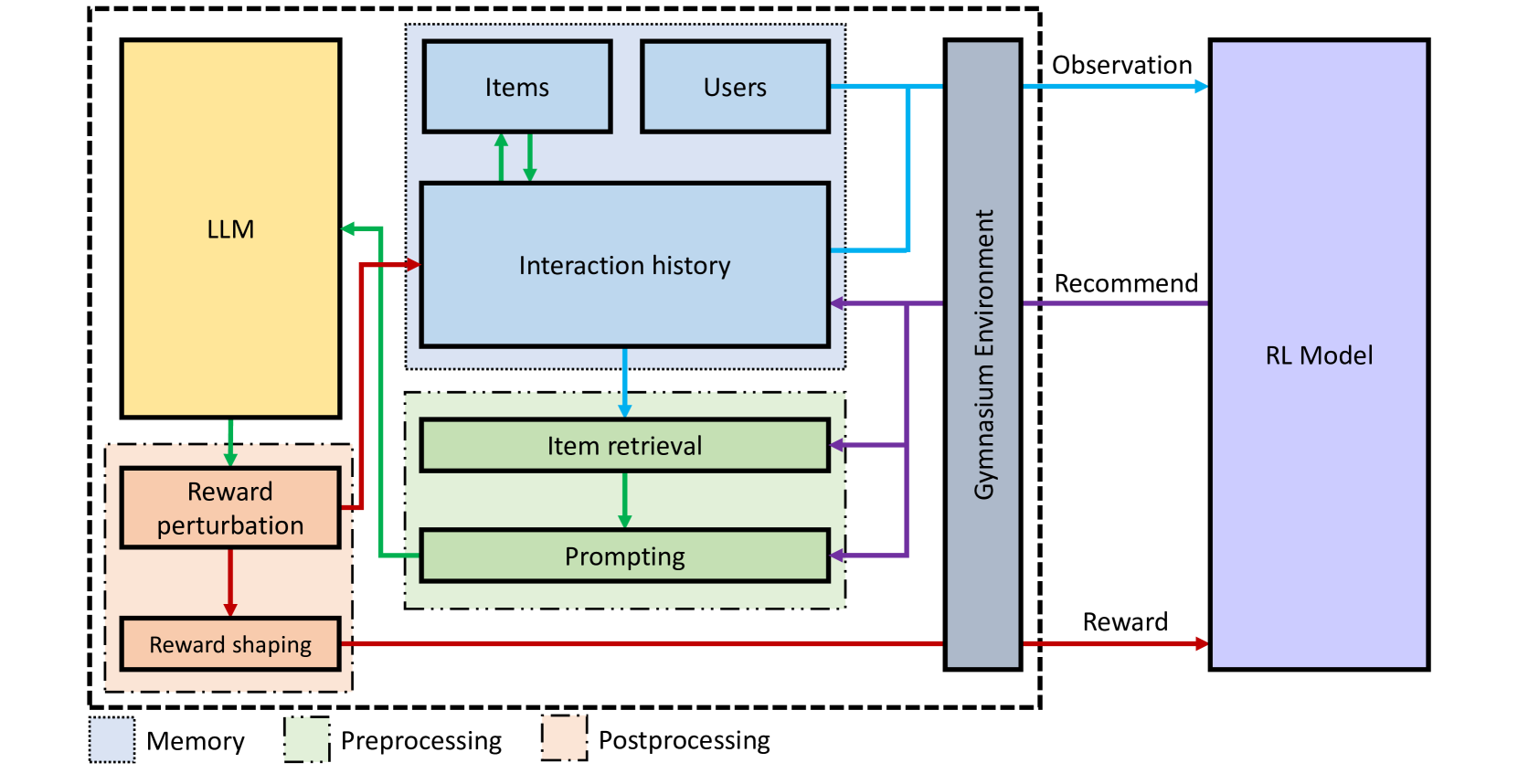
The overall architecture of the SUBER framework, illustrating the interaction loop between the RL Agent and the Synthetic Environment.
Evaluation Highlights
- Successfully replicates rating distributions of real-world datasets (MovieLens and Amazon Books) using synthetic LLM users
- Demonstrates that LLM agents can maintain consistent genre preferences (high ratings for liked genres, low for disliked) across interactions
- Validates the ability to use historical interaction data to predict future ratings for item sequences (e.g., movie series like James Bond)
Breakthrough Assessment
7/10
A strong application of LLMs as simulators rather than recommenders. While the concept of LLM agents is known, wrapping it into a standardized Gym environment for RL4Rec addresses a major pain point in the field (lack of online simulators).