📝 Paper Summary
Cold-Start Recommendation
Click-Through Rate (CTR) Prediction
Multimodal Representation Learning
IDProxy mitigates the item cold-start problem by using multimodal LLMs to generate proxy embeddings from content that are explicitly aligned with the collaborative ID embedding space of existing production CTR models.
Core Problem
Standard CTR models rely on item ID embeddings learned from interaction history, which fail for new items (cold-start) that lack this history.
Why it matters:
- New items are continuously uploaded on platforms like Xiaohongshu and must be served immediately to ensure user experience, but lack the data needed for collaborative filtering
- Existing solutions like simple MLP mappings fail to bridge the semantic gap between rich multimodal content and the irregular, non-clustered distribution of industrial ID embeddings
- Retraining or significantly altering mature industrial ranking models to accommodate new content features is costly and operationally complex
Concrete Example:
A newly uploaded post with an image and text has no click history, so its ID embedding is randomly initialized or poorly trained, causing the CTR model to rank it incorrectly. Existing methods might map its image features to an ID vector using a simple projection, but this vector often lands in a 'void' area of the ID space, disconnected from the collaborative patterns the ranker understands.
Key Novelty
Coarse-to-Fine Proxy Alignment with Multimodal LLMs (MLLMs)
- Stage 1 (Coarse): Uses an MLLM to generate a global content embedding, aligned to the static ID space via contrastive learning against mature items
- Stage 2 (Fine): Extracts multi-layer hidden states from the MLLM and refines them via an adaptor trained end-to-end with the frozen CTR ranker, allowing the proxy to learn ranker-specific structural priors
Architecture
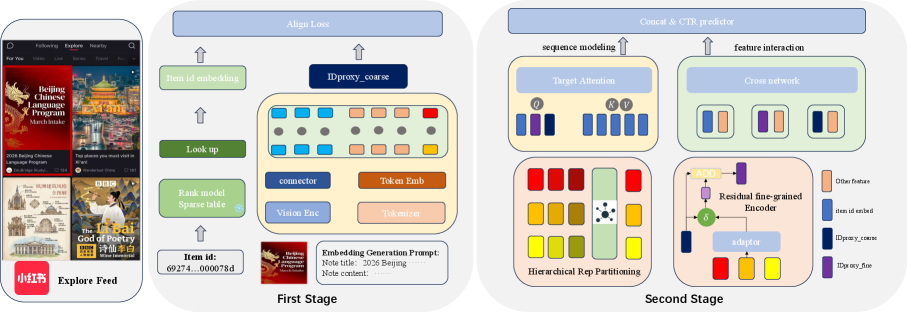
The IDProxy framework illustrating the two-stage training process: MLLM-based coarse proxy generation and CTR-aware fine-grained alignment.
Breakthrough Assessment
7/10
Offers a practical, production-proven method for aligning MLLM representations with legacy ID-based systems without requiring a full model redesign. High industrial value, though the core concept of 'content-to-ID' mapping is established.