📝 Paper Summary
Explainable Recommendation
LLM-based User Simulation
HF4Rec replaces sparse human feedback with LLM-simulated rewards to optimize recommendation explanations via reinforcement learning, using Pareto optimization to balance conflicting qualities like informativeness and persuasiveness.
Core Problem
Traditional explainable recommendation relies on supervised learning that blindly mimics ground truth reviews, failing to identify potentially superior generated explanations due to data sparsity and lack of human feedback.
Why it matters:
- Supervised text-fitting restricts models from exploring unobserved, high-quality explanations, limiting generalization
- Real-time human feedback for training is prohibitively expensive and slow
- Evaluation criteria for explanations are multi-faceted (e.g., persuasiveness vs. informativeness) and often contradictory, making simple optimization difficult
Concrete Example:
A user buys a skincare product ($v_2$). The ground truth review is generic: 'It feels nice on my skin'. If the model generates a more detailed explanation like 'My skin feels softer and smooth as it absorbs quickly', supervised learning penalizes it for not matching the target text, even though it is more informative and persuasive.
Key Novelty
Human-Like Feedback-Driven Optimization (HF4Rec)
- Uses Large Language Models as 'Human Simulators' to generate reward scores for explanations, effectively creating synthetic feedback for unobserved user-item pairs
- Employs a retrieval-augmented prompting strategy to extract user interests from noisy history and induce personalized scoring criteria
- Transforms the multi-perspective quality enhancement (balancing informativeness vs. persuasiveness) into a dynamic Pareto optimization problem to improve all objectives simultaneously
Architecture
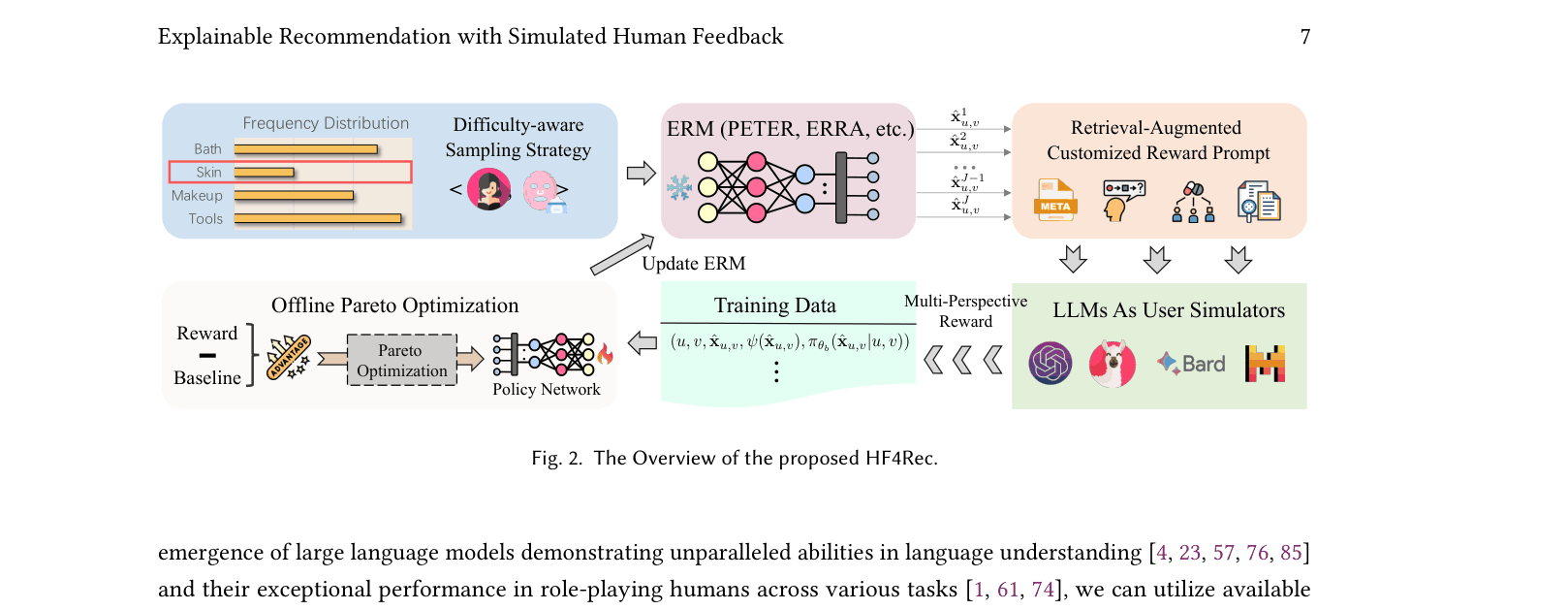
Overview of the HF4Rec framework showing the interaction between the Explainable Recommendation Model (ERM), the LLM User Simulator, and the Pareto Optimization loop.
Evaluation Highlights
- No quantitative results reported in the provided text
- Qualitative superiority claimed over baselines in generating human-aligned explanations
- Pareto optimization theoretically guarantees finding a gradient direction that improves all objectives simultaneously
Breakthrough Assessment
7/10
Novel application of RLAIF to the specific domain of explainable recommendation, addressing the critical 'ground truth' problem in text generation. The theoretical integration of Pareto optimization is strong.