📝 Paper Summary
Prompt Engineering
Domain-Specific AI Assistants
This system generates context-aware prompt suggestions for domain-specific AI by combining retrieval-augmented skill discovery with a telemetry-based ranking model to align user intent with available system capabilities.
Core Problem
Users in specialized domains (like cybersecurity) struggle to formulate precise prompts that align with complex system skills, while static recommendation lists lack context and scalability.
Why it matters:
- Ineffective prompts in high-stakes environments (e.g., security operations) lead to missed insights and operational inefficiencies
- Static prompt lists require manual curation and fail to scale as AI systems add new plugins and skills
- Generic suggestions ignore user history and active session context, failing to leverage behavioral telemetry for personalization
Concrete Example:
In a cybersecurity session analyzing a specific threat, a static system might suggest a generic 'Scan network' prompt. The proposed system, detecting the user is analyzing an 'Intune' device entity, retrieves the specific 'Intune Device Query' skill and synthesizes a precise prompt like 'List recent configuration changes for device [DeviceID]'.
Key Novelty
Context-Aware Hierarchical Prompt Synthesis
- Utilizes a two-stage hierarchical retrieval process that first identifies relevant 'plugins' (groups of skills) and then specific skills, similar to schema refinement
- Integrates a predictive model trained on behavioral telemetry (user clicks/history) to dynamically rank skills before generating the final natural language prompt
- Synthesizes the final prompt using an LLM that acts as an interpreter mapping user context and ranked skills to executable instructions
Architecture
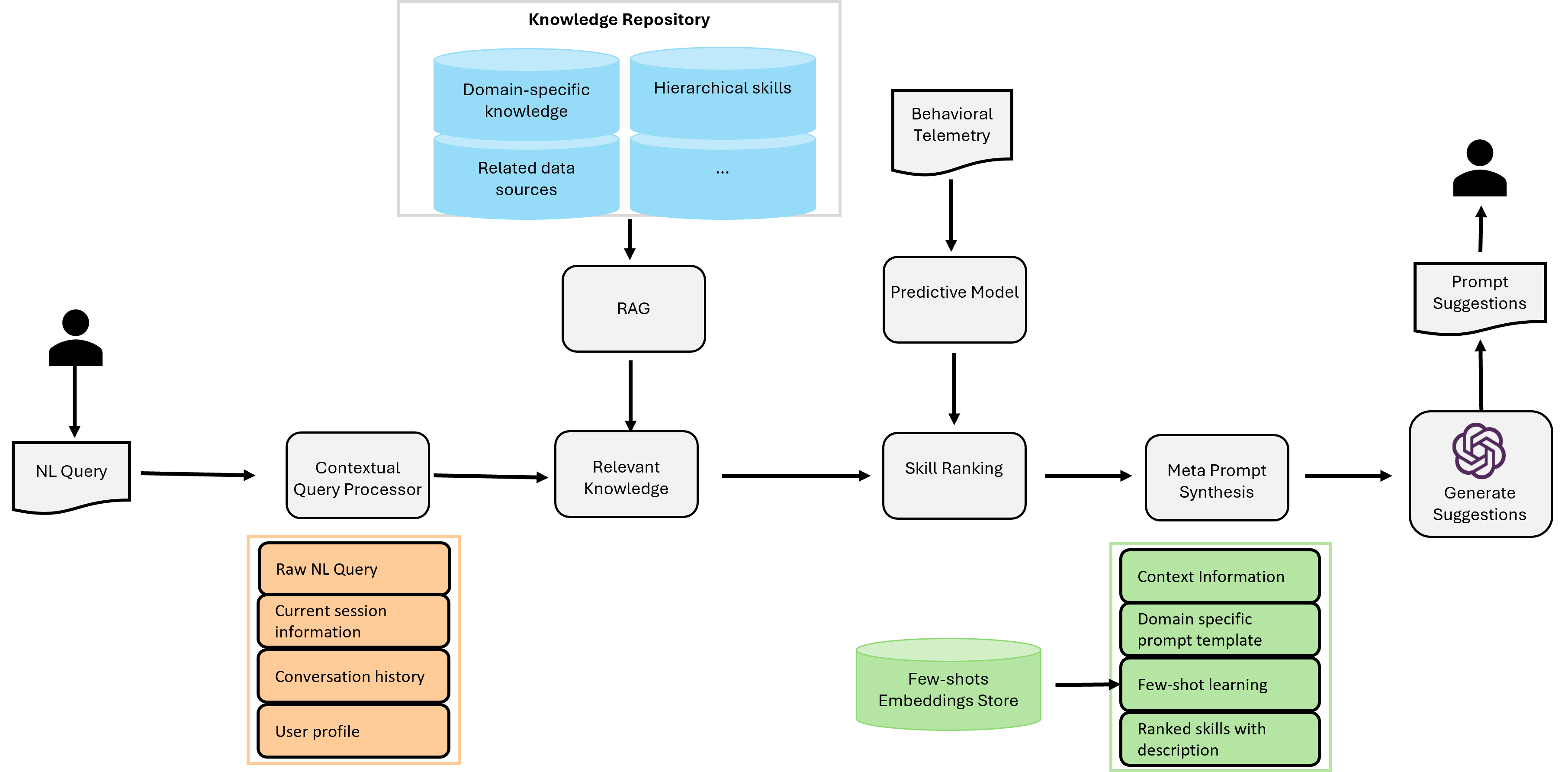
The end-to-end architecture of the dynamic prompt recommendation system
Evaluation Highlights
- 98.0% of suggested prompts were rated as 'Useful' or better by security researchers when using the full GPT-4o pipeline
- 75.0% of prompts generated by the full pipeline were rated 'Extremely Useful' by experts, significantly outperforming hybrid configurations
- Achieved 88.4% average usefulness score across 12,432 automated evaluations in real-world security customer sessions
Breakthrough Assessment
7/10
Strong practical application resolving a major usability bottleneck in domain-specific AI (discovery of complex skills). While components (RAG, Ranking) are known, their hierarchical integration for prompt suggestion is novel and effective.