📝 Paper Summary
LLM Recommendation Systems
Efficient Training
DTI significantly speeds up LLM training for CTR prediction by packing multiple target interactions into a single prompt with windowed causal attention, avoiding redundant context re-encoding.
Core Problem
Training LLMs for CTR prediction using the standard 'sliding-window' paradigm is computationally expensive because it scales linearly with interaction length (O(mn^2)), leading to massive redundancy.
Why it matters:
- LLM-based recommendation systems significantly outperform conventional models but are currently too slow to train on large datasets due to context length
- Existing sliding-window approaches force the model to re-encode substantially overlapping context sequences for every single target item
- The quadratic complexity of attention combined with long textual descriptions of items makes scaling to long user interaction sequences prohibitively costly
Concrete Example:
In the standard approach, to predict user interest in item t, the model processes items [t-n...t-1]. To predict for item t+1, it processes [t-n+1...t]. These two contexts overlap almost entirely, yet the model re-computes everything from scratch for each separate prompt.
Key Novelty
Dynamic Target Isolation (DTI)
- Constructs a single 'streaming prompt' containing *k* consecutive target items (instead of 1), allowing the model to reuse hidden states from previous targets within the same forward pass
- Applies a 'windowed causal attention' mask to ensure each target only attends to its valid preceding *n* context items, preventing information leakage from future tokens or extended history
- Eliminates absolute position IDs in favor of relative distance encoding to prevent the model from overfitting to the specific position of a target within the packed prompt
Architecture
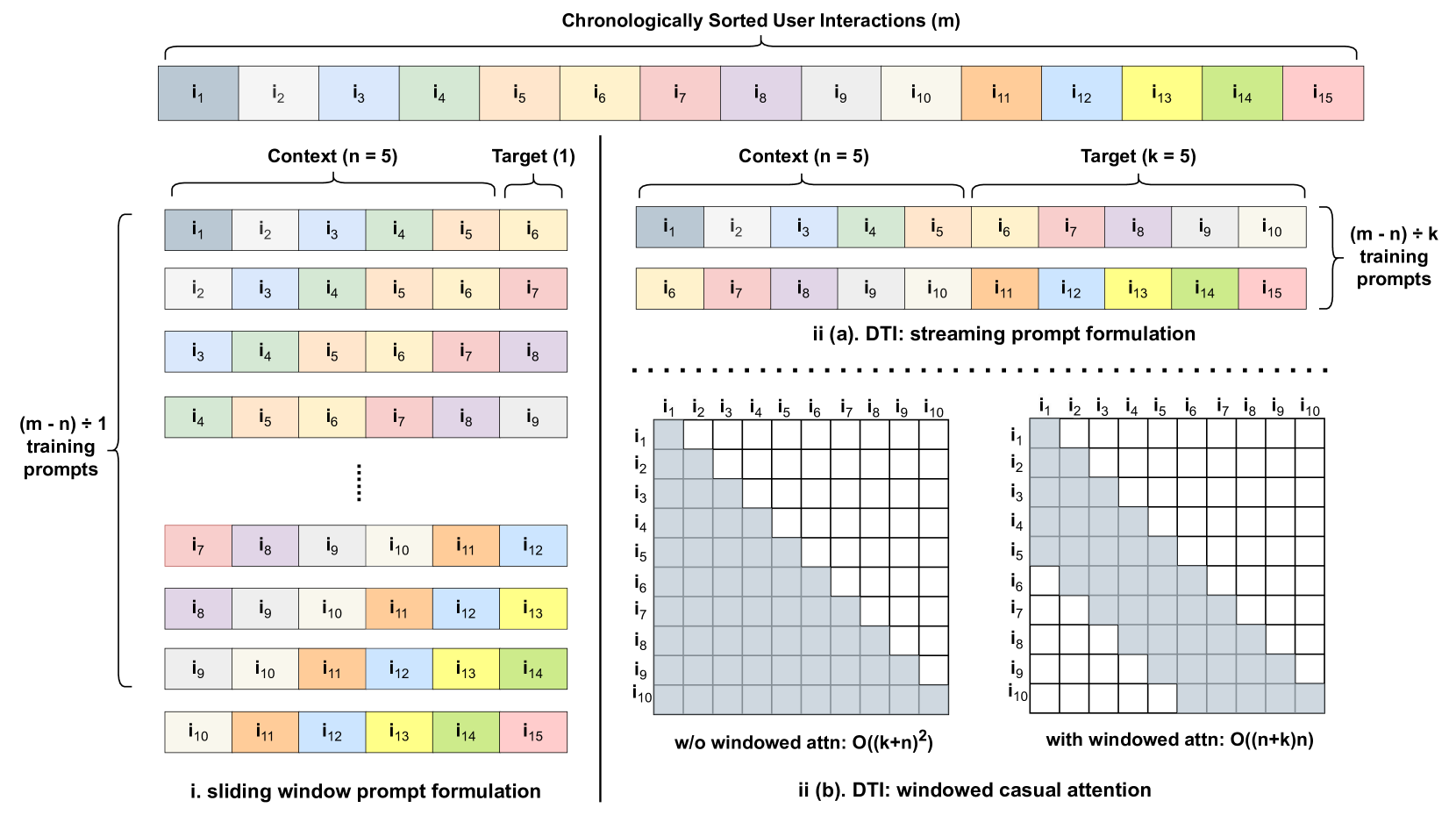
Comparison of Sliding Window vs. Dynamic Target Isolation (DTI) prompt formulation and attention masks.
Evaluation Highlights
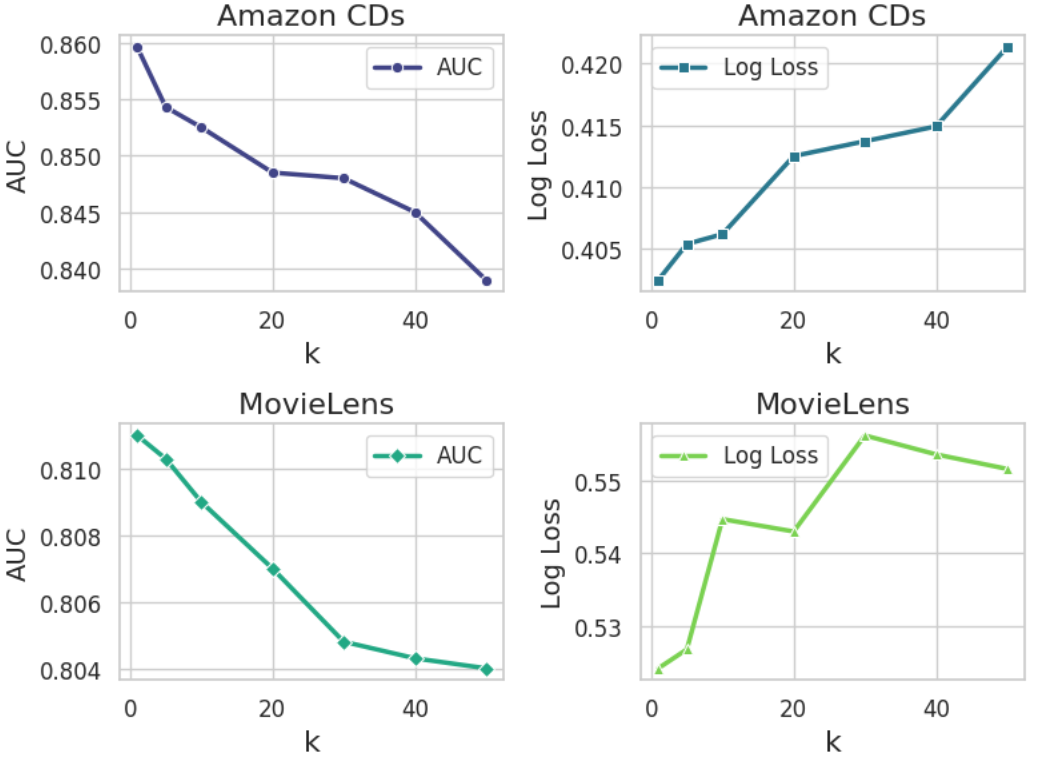
- Reduces training time by an average of 92% across three datasets (e.g., from 70.5 hours to 5.31 hours) compared to sliding-window
- Reduces theoretical FLOPs by approximately 14.28x when using a target stride of k=50 and context n=20
- Maintains CTR prediction performance (AUC/F1) comparable to the computationally expensive sliding-window baseline, provided leakage and positional bias are addressed
Breakthrough Assessment
8/10
Offers a massive efficiency gain (10x+) for a critical industrial task (CTR prediction) with minimal performance loss. Solves specific technical hurdles (leakage/bias) that typically plague such efficiency hacks.