📝 Paper Summary
Denoising Recommender Systems
LLM-enhanced Recommendation
Negative Sampling
LLMHNI leverages Large Language Models to distinguish valuable hard negative samples from noisy interactions in recommender systems by analyzing semantic embeddings and performing logical reasoning on user-item relevance.
Core Problem
Standard denoising methods in recommender systems rely on loss values to identify noise, but 'hard' samples (valuable for learning) and 'noisy' samples (misclicks) exhibit similar loss patterns, leading to the removal of informative data.
Why it matters:
- Hard samples are theoretically and empirically vital for modeling accurate user preferences, but current denoisers mistakenly drop them.
- Implicit feedback (clicks) is inherently noisy due to position bias and misclicks, but separating this noise from difficult user interests solely via numerical patterns (collaborative signals) is insufficient.
Concrete Example:
A user might have high predicted probability for an item they haven't clicked. This could be a 'noisy' false positive (misclick) or a 'hard' sample (user likes it but hasn't seen it). A loss-based denoiser sees high loss for both and drops both. LLMHNI uses LLM reasoning to see if the item actually matches the user's interest profile (Hard) or not (Noisy).
Key Novelty
LLM-enhanced Hard-Noisy sample Identification (LLMHNI)
- Utilizes **Semantic Relevance**: Projects LLM-encoded text embeddings into the recommendation space to identify 'hard negatives'—items the model predicts highly but which have low semantic similarity to the user.
- Utilizes **Logical Relevance**: Prompts an LLM to explicitly reason about the logical connection between a user and item (User-Centric and Item-Centric), constructing a refined interaction graph that includes 'hard' samples while filtering 'noise'.
- Uses **Cross-Graph Contrastive Alignment** to enforce consistency between the original interaction graph and the LLM-refined graph, suppressing hallucinations via edge-dropping augmentation.
Architecture
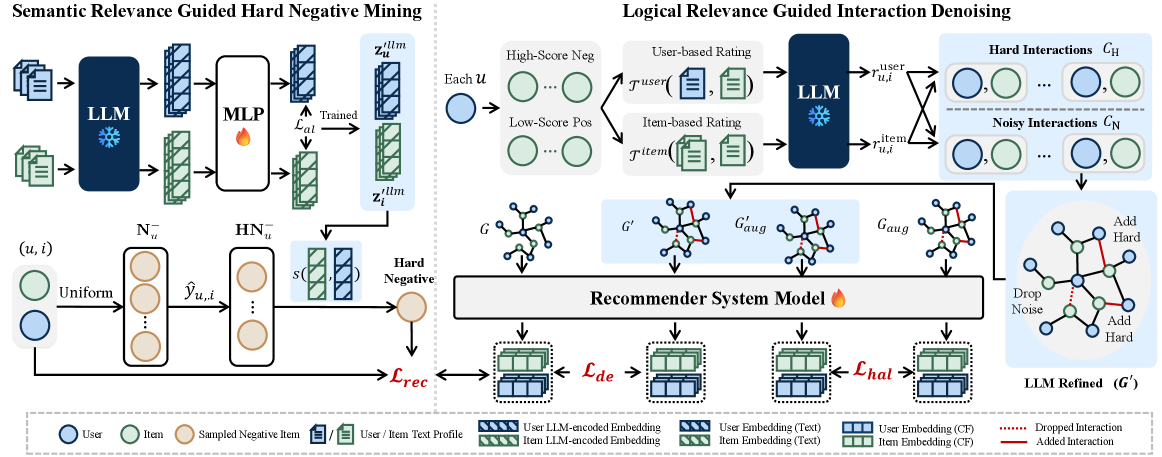
The overall LLMHNI framework, illustrating the two parallel modules: Semantic Relevance Guided Hard Negative Mining (left) and Logical Relevance Guided Interaction Denoising (right).
Breakthrough Assessment
7/10
Addresses a subtle but critical failure mode in denoising (hard vs. noise confusion) using a well-structured dual-signal approach (semantic + logical). The addition of hallucination mitigation makes it robust.