📝 Paper Summary
Generative Recommendation
LLM-based Recommendation
SETRec represents items as sets of order-agnostic tokens (combining semantic and collaborative filtering embeddings) to enable efficient, simultaneous generation without the local optima issues of sequential beam search.
Core Problem
Existing item identifiers for LLM recommenders are either token sequences (slow, prone to beam search local optima) or single tokens (fail to capture both semantic and collaborative filtering information).
Why it matters:
- Sequential generation (token-by-token) is computationally expensive and slow, hindering real-world deployment
- Beam search greedily prunes low-probability prefixes, missing optimal items if the initial tokens don't align perfectly with user preference
- Single-token approaches lose critical information: ID embeddings struggle with cold-start items, while semantic embeddings miss user behavior patterns (collaborative filtering)
Concrete Example:
In beam search, if the target item is 'Air Jordan', but the user's history suggests 'Nike', the model might generate 'Nike' first. If 'Air' has low probability initially, the correct sequence 'Air Jordan' is pruned early, leading to a suboptimal recommendation.
Key Novelty
Set-based Item Identifier (SETRec)
- Represents each item not as a sequence, but as a set of independent embeddings: one for collaborative filtering (user behavior) and several for semantic features (content)
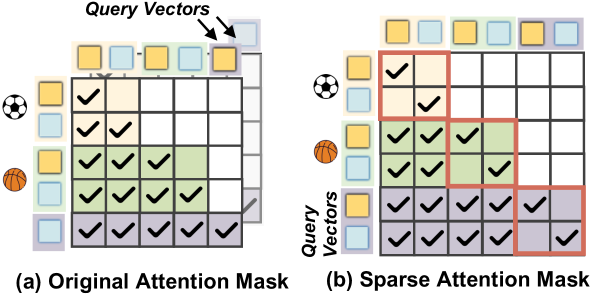
- Uses a sparse attention mask during user history encoding to remove dependencies between tokens of the same item, ensuring order invariance
- Employes query-guided simultaneous generation, where learnable query vectors prompt the LLM to generate all embedding components at once, avoiding autoregressive delays
Architecture
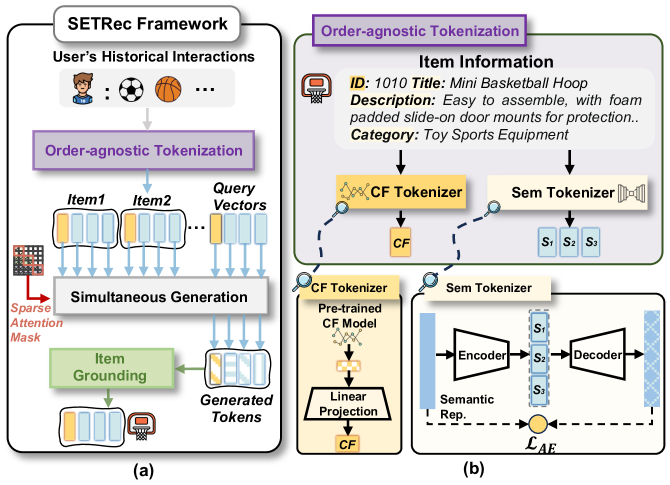
The overall SETRec framework, illustrating the item tokenization process (left) and the simultaneous generation inference flow (right)
Evaluation Highlights
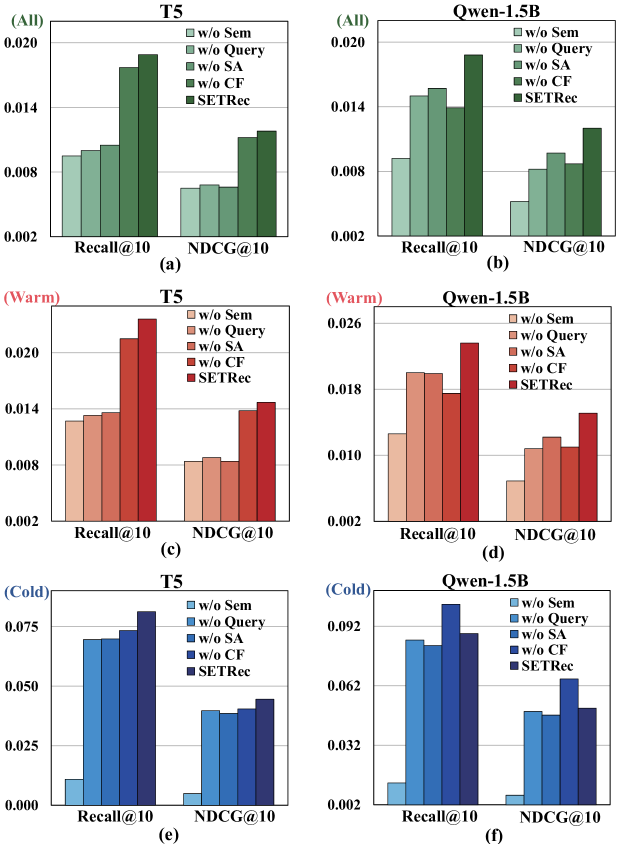
- Outperforms state-of-the-art baselines on 4 datasets; e.g., +26.04% improvement in NDCG@5 on the Sports dataset compared to TIGER
- Reduces inference latency significantly: approx 2.5x faster than sequential methods (TIGER) and comparable to single-token methods (E4SRec) while maintaining higher accuracy
- Achieves superior cold-start performance, improving NDCG@5 by roughly 2x on cold items in the Beauty dataset compared to LC-Rec
Breakthrough Assessment
8/10
Strong contribution addressing the two biggest bottlenecks in LLM recommendation: inference speed and the integration of ID vs. semantic signals. The simultaneous generation mechanism is a clever architectural shift from standard autoregression.