📝 Paper Summary
Cross-Domain Recommendation
Generative Recommendation
GenCDR replaces traditional item IDs with generative semantic IDs that dynamically fuse universal meaning and domain-specific traits, enabling effective cross-domain recommendation without shared identifiers.
Core Problem
Traditional cross-domain recommendation relies on shared IDs which are often unavailable, while current LLM-based methods suffer from tokenization gaps (vocabulary explosion) and fail to disentangle universal vs. domain-specific interests.
Why it matters:
- Real-world platforms often lack aligned user/item IDs across domains (e.g., online content vs. offline services), rendering ID-based methods ineffective.
- Existing LLM methods treat items as plain text or rigid indices, missing the nuanced evolution of user interests where the same concept (e.g., 'Apple') has different meanings across domains (tech vs. food).
Concrete Example:
An 'Apple Watch' in a tech domain and a fresh 'Apple' in a lifestyle domain share the concept 'Apple'. Standard methods might confuse them or fail to capture that 'health' is key for the watch while 'sweet' is key for the fruit. GenCDR disentangles these by generating distinct but related semantic IDs.
Key Novelty
Generative Cross-Domain Recommendation with Domain-Adaptive Semantic IDs
- Replaces arbitrary item IDs with discrete 'Semantic IDs' (SIDs) derived from text, ensuring items with similar meanings have similar codes even across domains.
- Uses a 'Domain-Adaptive Tokenization' module that generates these SIDs by routing between a frozen universal encoder (capturing shared semantics) and domain-specific adapters (capturing unique traits).
- Models user interests by dynamically fusing universal and domain-specific prediction distributions during the autoregressive generation process.
Architecture
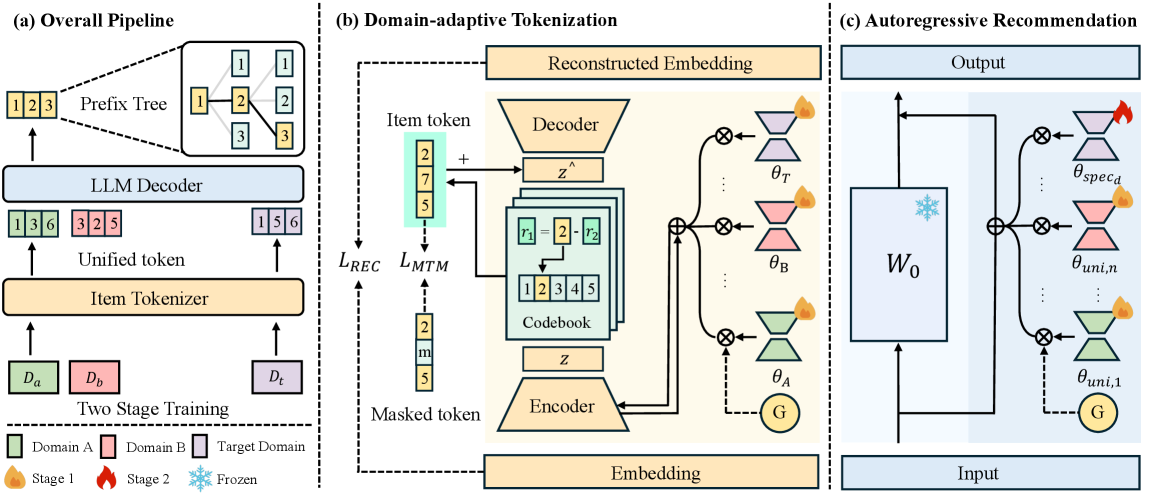
The complete GenCDR framework, illustrating the two main parallel tracks: Item Tokenization (left) and User Recommendation (right), and their convergence during inference.
Evaluation Highlights
- Significantly outperforms state-of-the-art baselines on multiple real-world datasets (exact improvement metrics not extracted from text but claimed as significant).
- Effectively resolves the item tokenization dilemma by generating compact, transferable semantic IDs instead of expanding vocabulary.
- Demonstrates superior generalization by effectively transferring knowledge even when user/item overlaps are sparse or non-existent.
Breakthrough Assessment
8/10
Novel approach to the 'ID problem' in cross-domain recommendation by moving to generative semantic IDs. The dual disentanglement (item-level and user-level) is theoretically sound and addresses a major bottleneck in LLM-based RecSys.