📝 Paper Summary
Recommender Systems
Entity Matching
Conversational Recommender Systems (CRS)
Reddit-Amazon-EM is a manually annotated benchmark linking unstructured movie mentions from Reddit conversations to structured Amazon catalog entries, demonstrating that graph-based and LLM-driven methods significantly outperform traditional lexical matching.
Core Problem
Conversational Recommender Systems (CRS) struggle to link ambiguous, informal item mentions in user queries (like Reddit posts) to structured catalog entities (like Amazon products) due to a lack of rigorous cross-dataset evaluation benchmarks.
Why it matters:
- In-the-wild user queries lack structured metadata, hindering the development of knowledge-aware recommender systems that need accurate grounding
- Current CRS studies use ad-hoc matching (Fuzzy, BM25) without rigorous evaluation, leading to unreliable recommendations
- There is no consensus on which Entity Matching (EM) methods work best for linking diverse data formats like social media discussions to product catalogs
Concrete Example:
A Reddit user mentions 'Prisoners (2013)'. A simple text matcher might incorrectly link this to 'PRISONER' or 'Prison (Collector’s Edition)', whereas the correct Amazon entries are specific formats like 'Prisoners [DVD] (2013)' or 'Prisoners (Blu-ray+DVD)'.
Key Novelty
Reddit-Amazon-EM Benchmark
- Constructs a gold-standard dataset by manually annotating matches between informal Reddit movie titles and structured Amazon product entries, filtering out metadata mismatches like wrong years
- systematically evaluates five classes of Entity Matching methods (lexical, vector, hybrid, graph-based, LLM-based) on this specific cross-platform linking task
Architecture
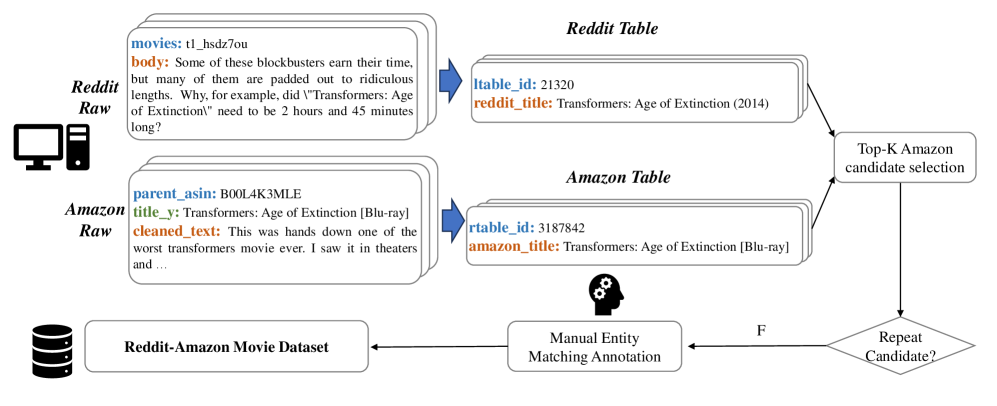
The data construction pipeline for Reddit-Amazon-EM, illustrating the flow from raw data to annotated gold set
Evaluation Highlights
- Graph-based GNEM achieves state-of-the-art performance with 96.29% F1, significantly outperforming traditional BM25 (78.43% F1) and Faiss (60.51% Precision at best F1 threshold)
- LLM-based ComEM follows closely with 94.02% F1, showing that semantic understanding beats lexical matching but still lags behind graph-based structural matching in precision
- In downstream CRS tasks, GNEM maintains the lead with 7.84% Recall@5 when used with GPT-3.5, validating the benchmark's relevance to real-world recommendation scenarios
Breakthrough Assessment
8/10
Provides a much-needed rigorous benchmark for a critical but neglected component of CRS. The manual annotation of >4k items is a significant resource contribution.