📝 Paper Summary
LLM for Recommendation (LLMRec)
Collaborative Filtering integration with LLMs
BinLLM integrates collaborative filtering into LLMs by converting latent user/item embeddings into binary sequences (and optionally dot-decimal notation) that LLMs can process as text features.
Core Problem
Collaborative information (user-item interaction patterns) exists in a different modality from text, making it difficult for LLMs to leverage directly without disrupting their original textual encoding capabilities.
Why it matters:
- Collaborative information is pivotal for modeling user interests but is essentially low-rank numeric data, unlike the semantic text LLMs are trained on.
- Existing methods that learn embeddings from scratch suffer from low efficacy due to the low-rank nature of the data.
- Methods mapping external embeddings to soft tokens introduce training overhead and alter the LLM's generative space, potentially compromising original functionalities.
Concrete Example:
A standard LLM sees a user ID 'User_123' as meaningless text. Current methods map this ID to a learned vector, but this vector isn't 'text-like'. BinLLM converts the ID's collaborative vector into a string like '10110...' or '172.16.254.1', which the LLM can process using its inherent ability to handle symbol sequences.
Key Novelty
Text-like Encoding (TE) via Binary Sequences
- Transforms continuous collaborative embeddings from a traditional recommendation model into discrete binary strings (e.g., '10110') using a hash-like binarization layer.
- Optionally compresses these long binary strings into dot-decimal notation (like IPv4 addresses, e.g., '192.168.1.1') to reduce token length while remaining interpretable to LLMs trained on web data.
Architecture
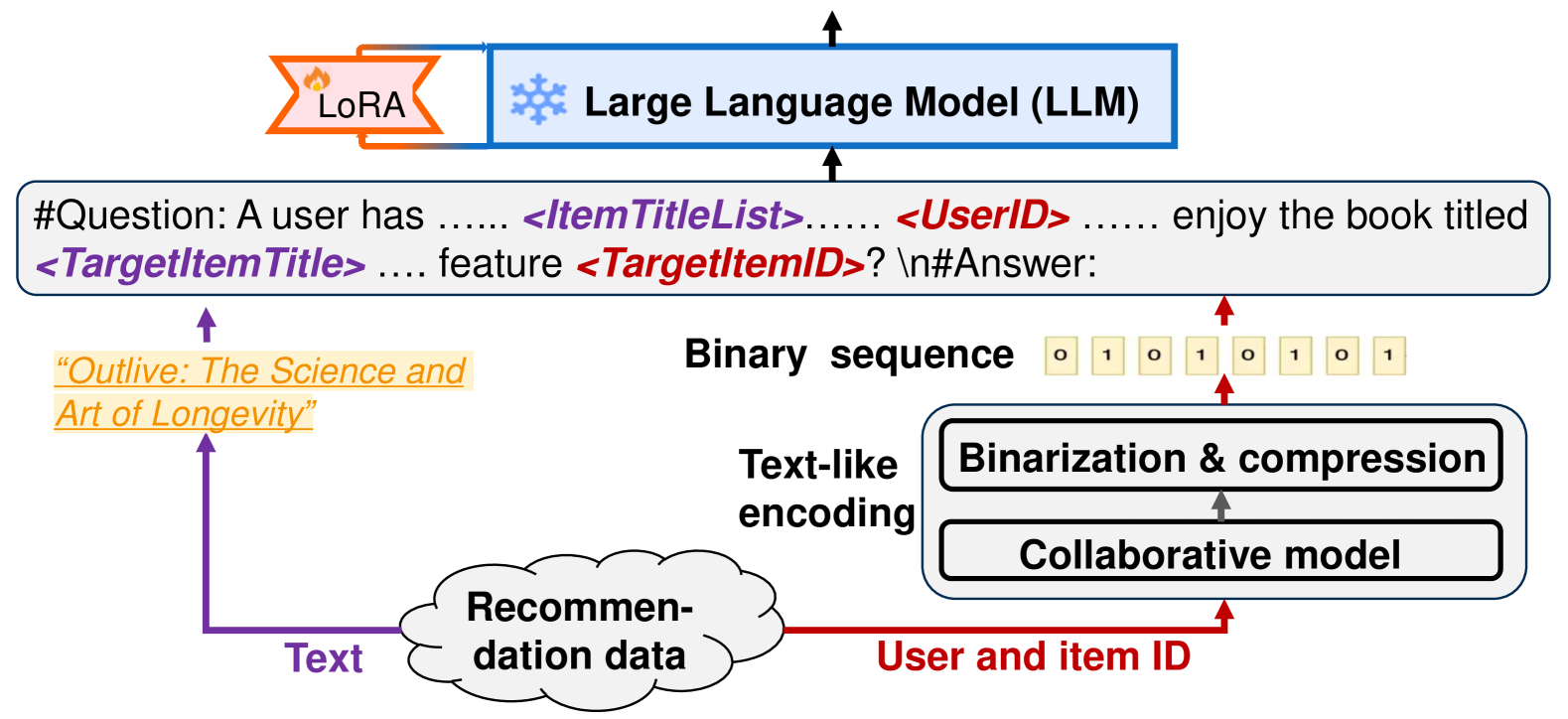
The overall framework of BinLLM, illustrating how user/item IDs are processed into collaborative embeddings, binarized/compressed, and then inserted into a text prompt for the LLM.
Evaluation Highlights
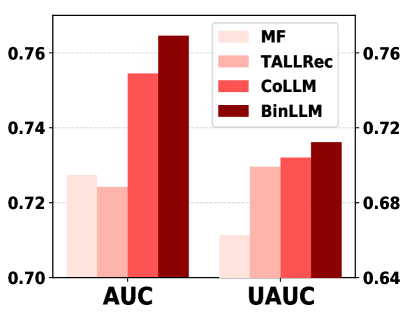
- Outperforms state-of-the-art LLMRec baseline (CoLLM) by +6.3% on NDGC@10 for the ML-1M dataset.
- Achieves 0.0805 NDGC@10 on ML-1M in warm-start scenarios, surpassing the best baseline (TALLRec) at 0.0631.
- Binary encoding strategy improves over non-collaborative LLM baselines (like standard Llama-2) significantly, validating the alignment of binary features with LLM capabilities.
Breakthrough Assessment
7/10
Clever and lightweight approach to the modality gap problem in LLMRec. Using IPv4-style notation is a novel insight into LLM priors, though the method is primarily an encoding trick rather than a fundamental architectural shift.