📊 Experiments & Results
Evaluation Setup
Reranking top-10 predictions from baseline recommenders (LightGCN, SASRec) using a Leave-One-Out strategy.
Benchmarks:
- Amazon Movies & TV (Movie Recommendation)
- Yelp (Business Recommendation)
- Goodreads (Book Recommendation)
Metrics:
- NDCG@10
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Amazon Movies & TV | NDCG@10 | 0.696 | 0.705 | +0.009 |
Experiment Figures
Impact of Position-Based Feedback (PBF) on NDCG@10 and Average Rank.
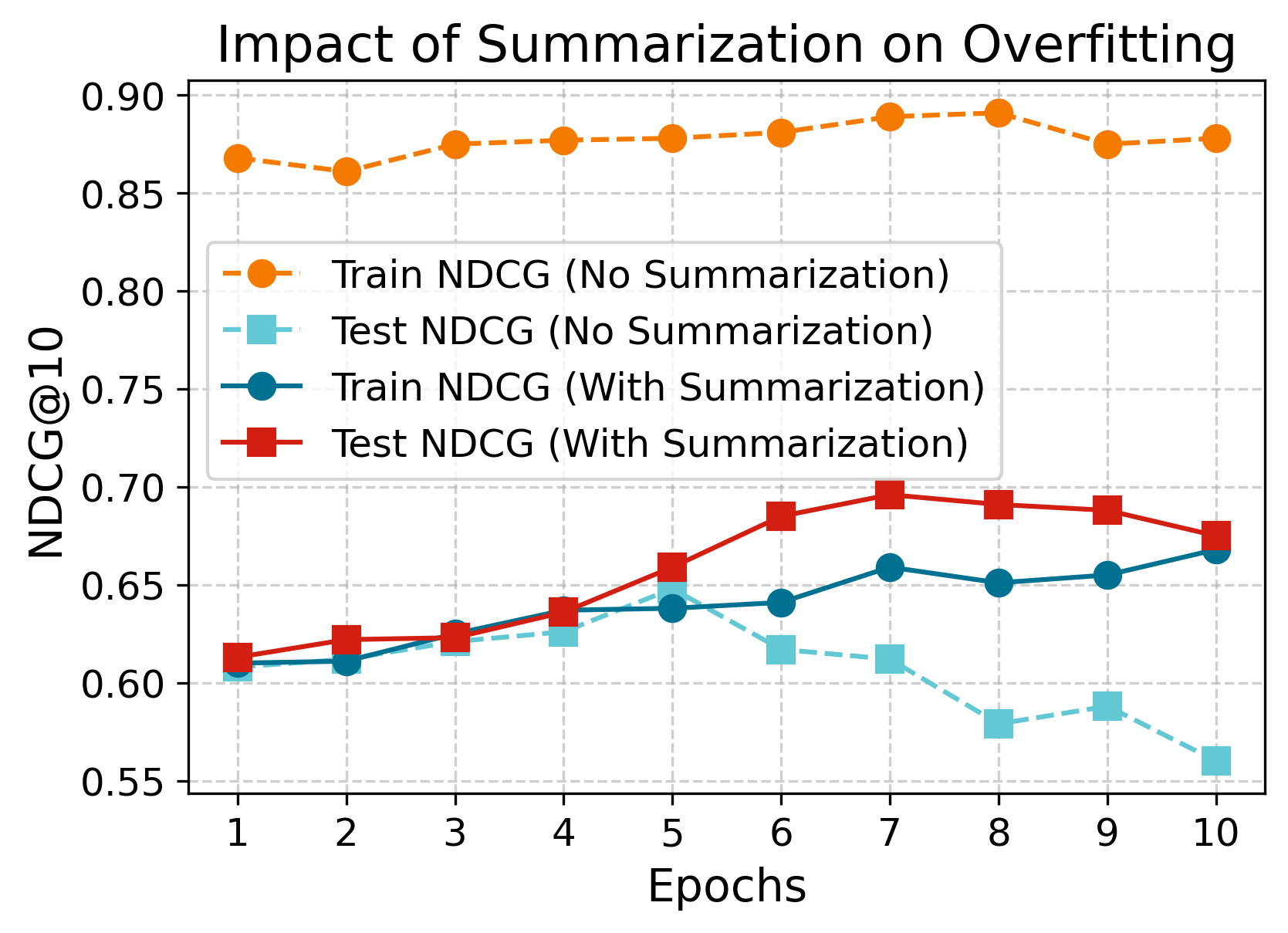
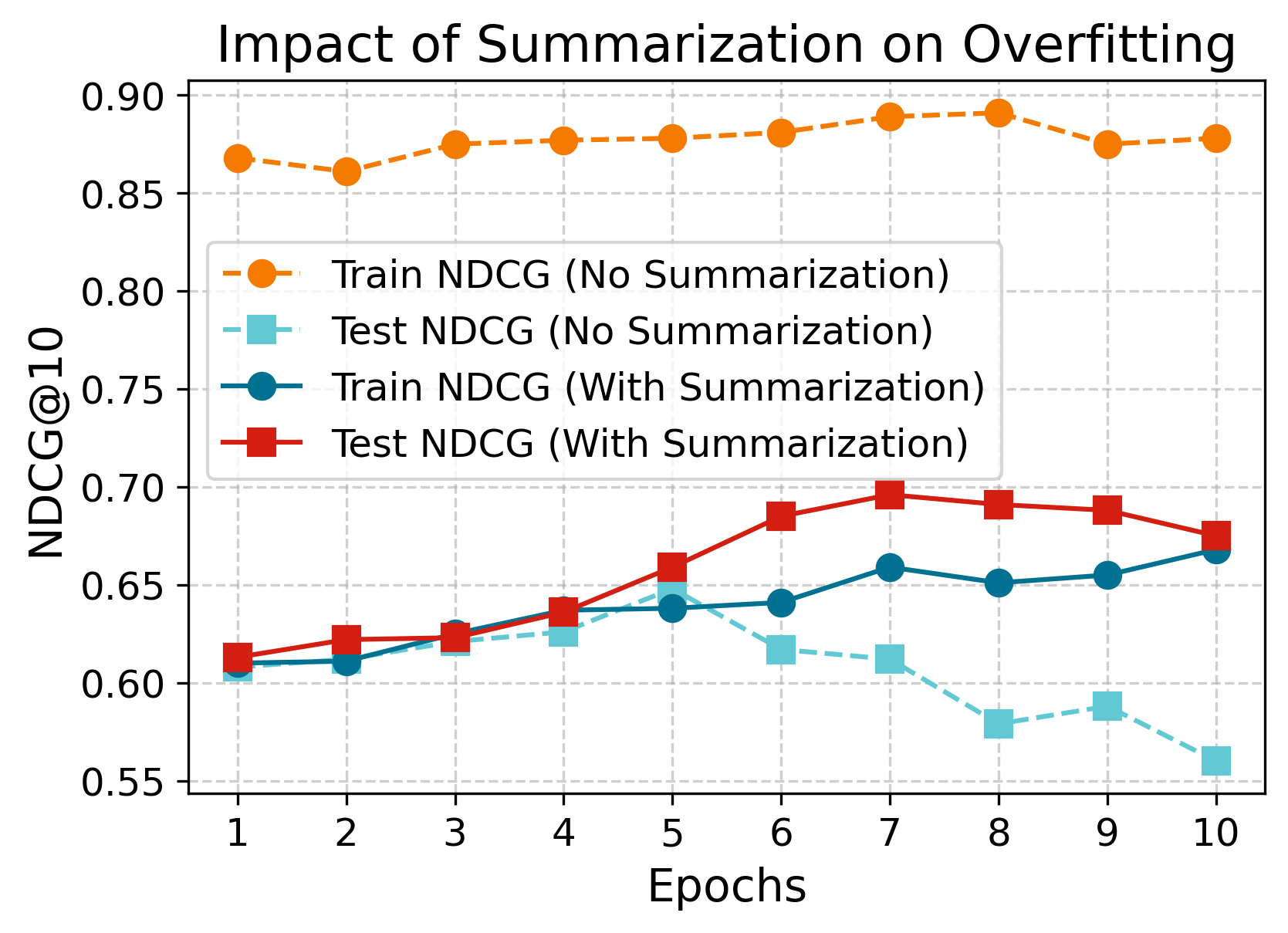
Impact of Summarization in Batched Training.
Main Takeaways
- AGP consistently outperforms static prompting baselines (LLM-Dir, LLM-CoT) by self-optimizing the profile generation prompt.
- Position-based feedback is more effective than aggregate metrics (like NDCG) for optimization because it provides interpretable, item-level correction signals.
- The method is highly data-efficient, achieving competitive results with just 100 training users.
- Performance gains are higher on graph-based baselines (LightGCN) than sequential ones (SASRec), likely because AGP adds sequential/semantic reasoning that LightGCN lacks.