📝 Paper Summary
Conversational Recommender Systems (CRS)
User Simulation
Human-AI Interaction
The paper introduces SalesOps, a framework for simulating and evaluating conversational recommender systems that educate users about complex products, revealing that LLM-based agents match human fluency but struggle with recommendation accuracy.
Core Problem
Existing Conversational Recommender Systems (CRS) focus on simple content domains (movies, books) where users have clear preferences, failing to address complex e-commerce scenarios where users lack background knowledge and have underspecified goals.
Why it matters:
- Buying complex products (e.g., TVs, appliances) requires domain expertise that most users lack, necessitating educational dialogue rather than just preference gathering
- Traditional 'System Ask-User Answer' paradigms fail when users cannot articulate their needs without first learning about product attributes
- Current evaluation methods rarely measure the educational value provided by the system or the faithfulness of sales strategies
Concrete Example:
A user shopping for a coffee maker might not know the difference between 'drip' and 'espresso' machines. A standard CRS asks for preferences immediately, whereas a helpful agent should explain these types first. In the paper's experiments, professional salespeople upsell or simplify technical details (unfaithfully) to close deals, a behavior difficult for current metrics to capture.
Key Novelty
SalesOps: A dual-agent simulation framework for educational e-commerce dialogue
- Introduces a 'Buying Guide' as a distinct knowledge source alongside the product catalog, enabling the Seller to proactively educate the Shopper
- Simulates underspecified goals by revealing Shopper preferences gradually during the chat only when relevant topics are discussed, rather than all at once
- Deploys two LLM-based agents (SalesBot and ShopperBot) to simulate the full interaction loop, facilitating scalable evaluation of educational value and recommendation quality
Architecture
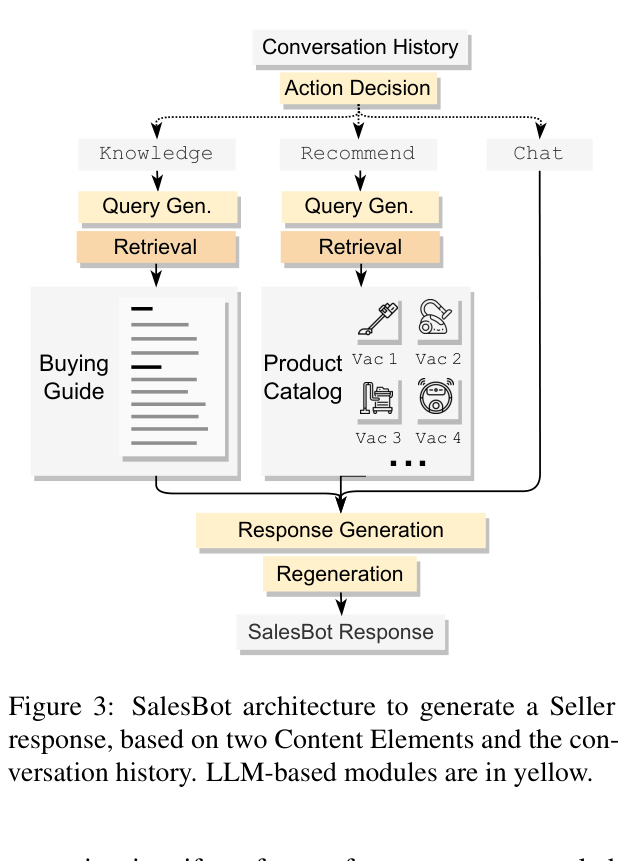
The architecture of SalesBot, detailing the flow from conversation history to tool selection and response generation.
Evaluation Highlights
- SalesBot matches professional salespeople in fluency (4.4 vs 4.2 Likert score) but lags in recommendation accuracy (44% vs 54%)
- Professional salespeople are identified as human 80% of the time, while SalesBot is identified as human only 55% of the time despite high fluency scores
- Faithfulness analysis reveals that ~25% of conversations from *both* SalesBot and human professionals contain unfaithful claims (e.g., hallucinations or upselling strategies)
Breakthrough Assessment
7/10
Significant contribution in defining a new problem space (educational CRS) and simulation framework. The finding that humans are also 'unfaithful' in sales contexts is a valuable insight for AI alignment.
