📝 Paper Summary
Conversational Recommender Systems (CRS)
Vision-Centric Text Processing
STARCRS improves conversational recommendation by rendering long, noisy textual contexts as images for coarse-grained skimming, while retaining standard text encoding for fine-grained reasoning on critical segments.
Core Problem
Enriching CRSs with external knowledge (retrieved dialogues, entity descriptions) creates long, heterogeneous, and noisy inputs that strain standard language models and lead to truncation of critical evidence.
Why it matters:
- Retrieved contexts often contain irrelevant chit-chat or unstructured attributes that confuse standard sequential tokenizers
- Strict token limits force models to discard potential preference signals when handling enriched contexts
- Current approaches treat all text as a flat sequence, ignoring layout structures that might indicate importance
Concrete Example:
A retrieved dialogue might contain lengthy greetings or filler utterances that push critical product mentions out of the LLM's context window. STARCRS renders this full history as an image to 'skim' the global context without truncation, while focusing text encoding on the most recent turns.
Key Novelty
Screen-Text-Aware Conversational Recommender System (STARCRS)
- Mimics human reading by splitting processing into two paths: a 'skim reading' path that encodes rendered text images for global context, and a 'careful reading' path that text-encodes specific salient segments
- Introduces a vision-centric encoder to CRSs that treats auxiliary text (like long entity descriptions or dialogue history) as visual tokens, making the system robust to layout variations and noise
Architecture
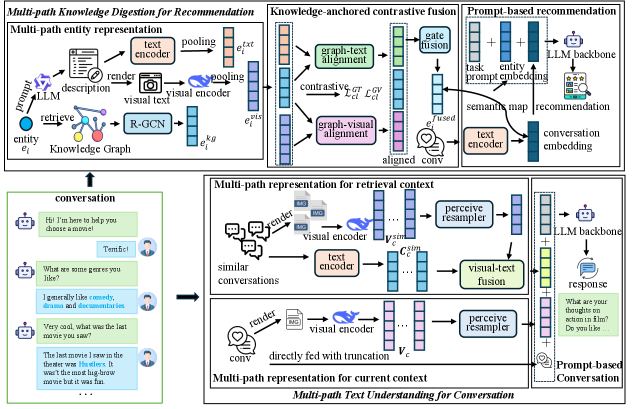
The overall architecture of STARCRS, showing the two main modules: Multi-path Knowledge Digestion for Recommendation and Multi-path Text Understanding for Conversation.
Evaluation Highlights
- Consistent improvements in recommendation accuracy (Hit@1, Hit@10) across distinct benchmarks (ReDial, TG-ReDial)
- Enhances response generation quality, evidenced by higher BLEU and distinct-ngram scores compared to text-only baselines
- Demonstrates robustness to noisy and lengthy inputs where standard text-based methods suffer from truncation or distraction
Breakthrough Assessment
7/10
Novel application of vision-centric text encoding (like pixel-based reading) to the specific domain of conversational recommendation. Addresses a real bottleneck (context length/noise) with a cognitively grounded solution.