📝 Paper Summary
Recommender Systems (RS) Evaluation
LLMs as Judges / LLM-based Evaluation
LLMs can assess serendipity in recommendations better than random baselines but struggle to align highly with human judgments, with performance heavily dependent on prompt design and history length.
Core Problem
Evaluating serendipity (unexpected relevance) in recommender systems is difficult because it is subjective, emotional, and typically requires costly user surveys rather than simple engagement metrics.
Why it matters:
- Traditional accuracy metrics promote over-specialization (filter bubbles), discouraging users from exploring new interests.
- Obtaining ground-truth serendipity labels via human surveys is expensive, inconsistent, and unscalable.
- A reliable automated proxy for human serendipity judgment is needed to optimize and evaluate serendipity-oriented algorithms at scale.
Concrete Example:
A user watches 'War Dogs' and is recommended 'Gosford Park'. Humans might find this serendipitous (unexpected but liked). An LLM needs to predict this 'Yes/No' judgment based only on the user's past movie ratings, a task where standard accuracy metrics fail.
Key Novelty
LLM-based Serendipity Assessment (LSA)
- Proposes using LLMs (GPT-3.5, GPT-4, Llama2) as binary classifiers to predict if a user finds a recommended item serendipitous.
- Investigates four prompt variations: implicit (titles only), explicit (titles+ratings), implicit+genres, and explicit+genres to determine optimal input context.
- Evaluates alignment with human ground truth from the Serendipity-2018 dataset, comparing LLMs against traditional recommender baselines.
Architecture
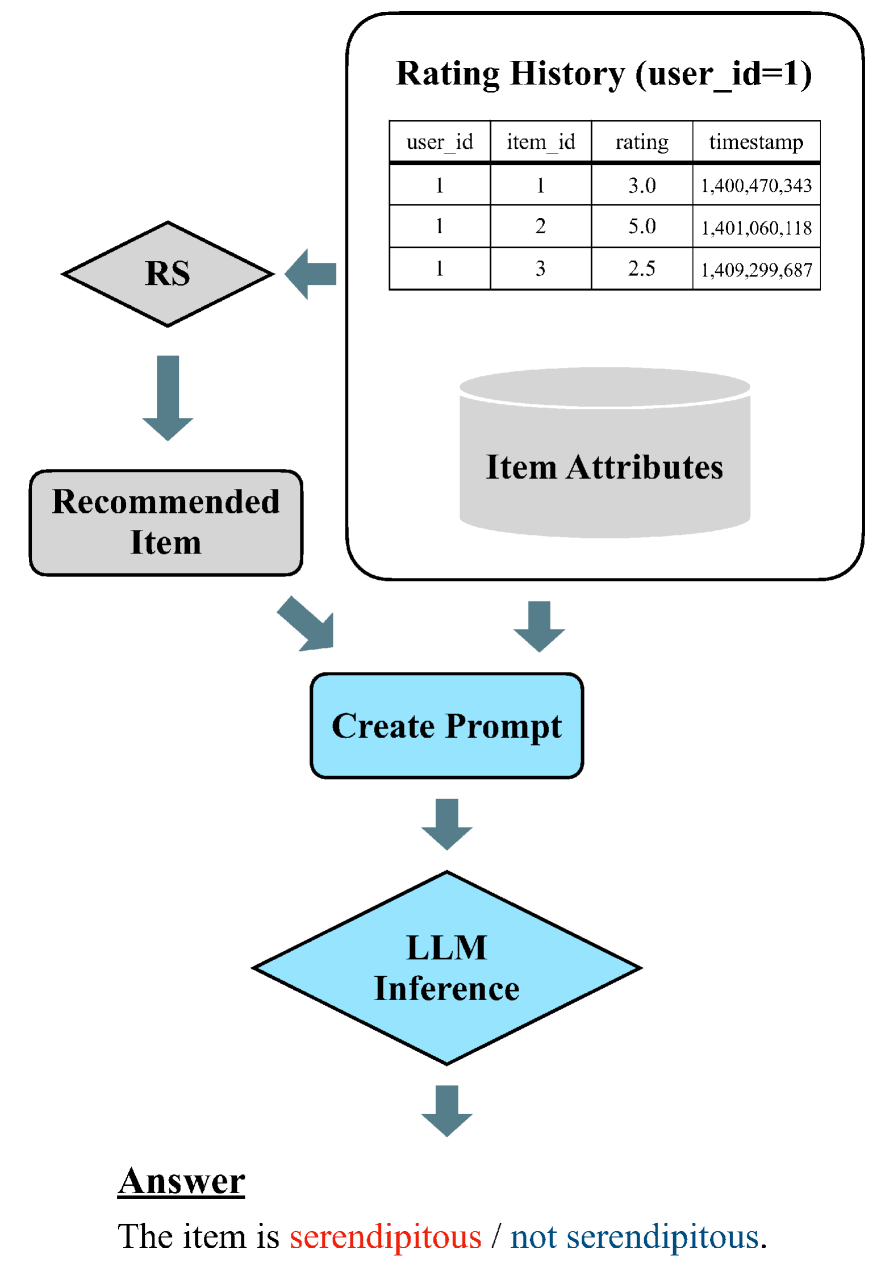
The proposed framework for serendipity assessment using LLMs.
Evaluation Highlights
- GPT-4 achieves the highest accuracy (0.876) among LLMs, outperforming random guessing and standard baselines like 'all negative'.
- LLMs generally struggle with Precision for the minority 'serendipitous' class (GPT-4 Precision: 0.207), often failing to identify true serendipity despite high accuracy.
- The method outperforms the Serendipity-Oriented Greedy (SOG) baseline algorithm in classification tasks, suggesting LLMs capture nuances better than simple heuristic re-ranking scores.
Breakthrough Assessment
4/10
First exploration of LLMs for this specific metric, showing potential but low agreement with humans. It highlights the difficulty of the task rather than solving it completely.