📝 Paper Summary
Conversational Recommendation Systems (CRS)
Preference Optimization (PO)
User Simulation
ECPO aligns conversational agents with user expectations by explicitly modeling satisfaction via Expectation Confirmation Theory to generate turn-level preference pairs without costly sampling.
Core Problem
Current conversational agents often generate short-sighted responses that fail to sustain long-term guidance, and existing multi-turn preference optimization methods are inefficient due to high sampling costs and noisy intermediate rewards.
Why it matters:
- Standard LLMs prioritize next-token prediction over long-term strategic guidance needed for recommendation
- Existing approaches like MCTS-based optimization require expensive self-sampling to estimate turn-level rewards, which is computationally prohibitive
- Randomness in simulated environments introduces noise into preference labels, degrading the alignment of the agent
Concrete Example:
In a recommendation dialogue, a standard agent might prematurely recommend an item before fully understanding preferences. ECPO identifies this 'short-sightedness' by comparing the response against user expectations (flexibility/coherence), triggering a rewrite to ask a clarifying question instead.
Key Novelty
Expectation Confirmation Preference Optimization (ECPO)
- Uses Expectation Confirmation Theory to simulate a user's inner monologue, assigning satisfaction scores to each turn based on flexibility, coherence, and guidance
- Identifies low-satisfaction turns and uses a 'Backward Expectation Derivation' process to rewrite them, creating high-quality preference pairs (original vs. rewritten) without self-sampling
- Introduces AILO, a user simulator based on Activities, Interests, Language, and Orientations to provide diverse feedback and perform the expectation confirmation process
Architecture
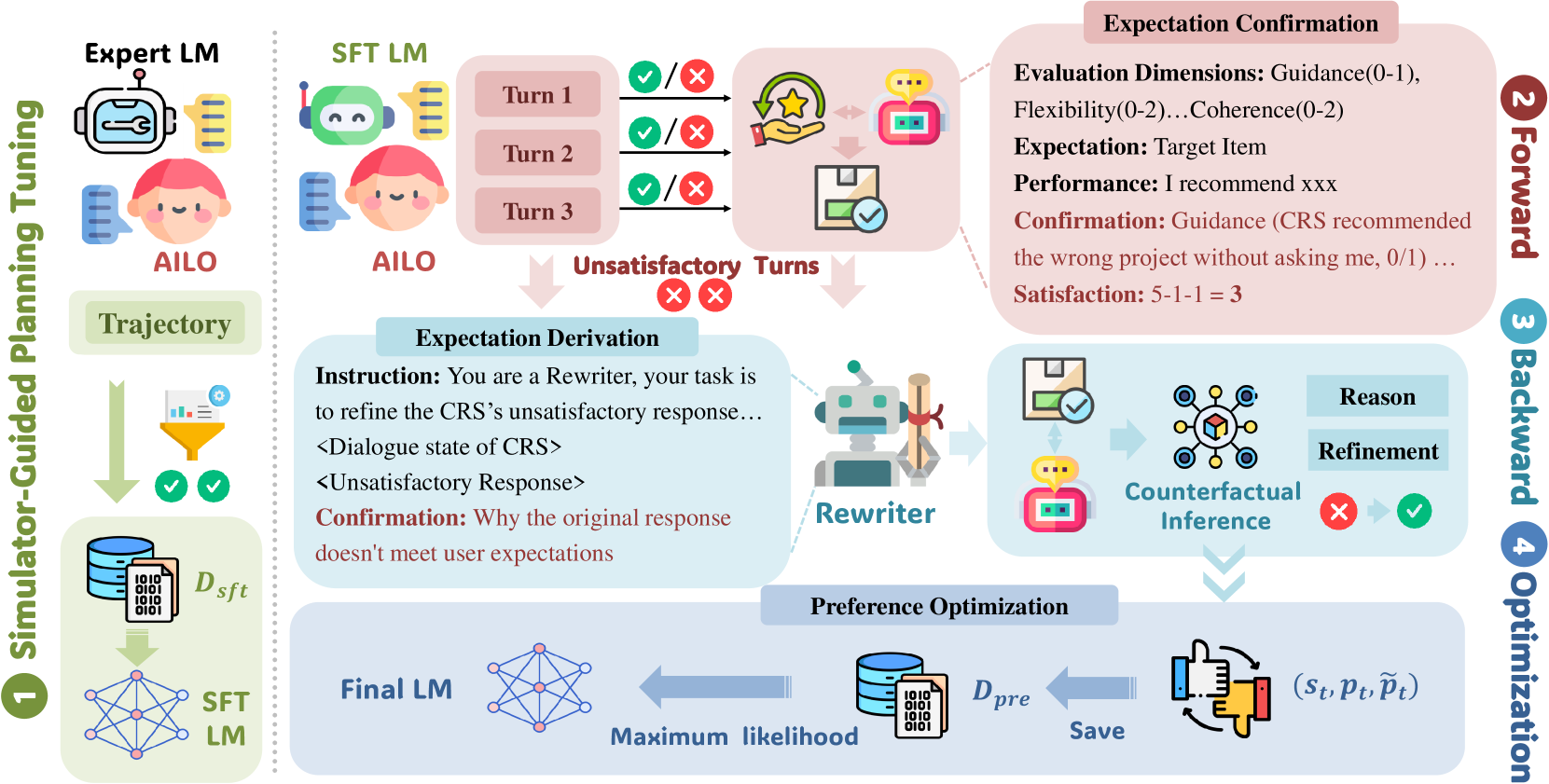
The complete ECPO pipeline: Simulator-Guided Planning Tuning, followed by the three-step optimization process (Forward Expectation Confirmation, Backward Expectation Derivation, Preference Optimization).
Evaluation Highlights
- Outperforms DPO and KTO baselines on turn-level win rates against GPT-4, achieving a 64.0% win rate on the Multi-WOZ dataset
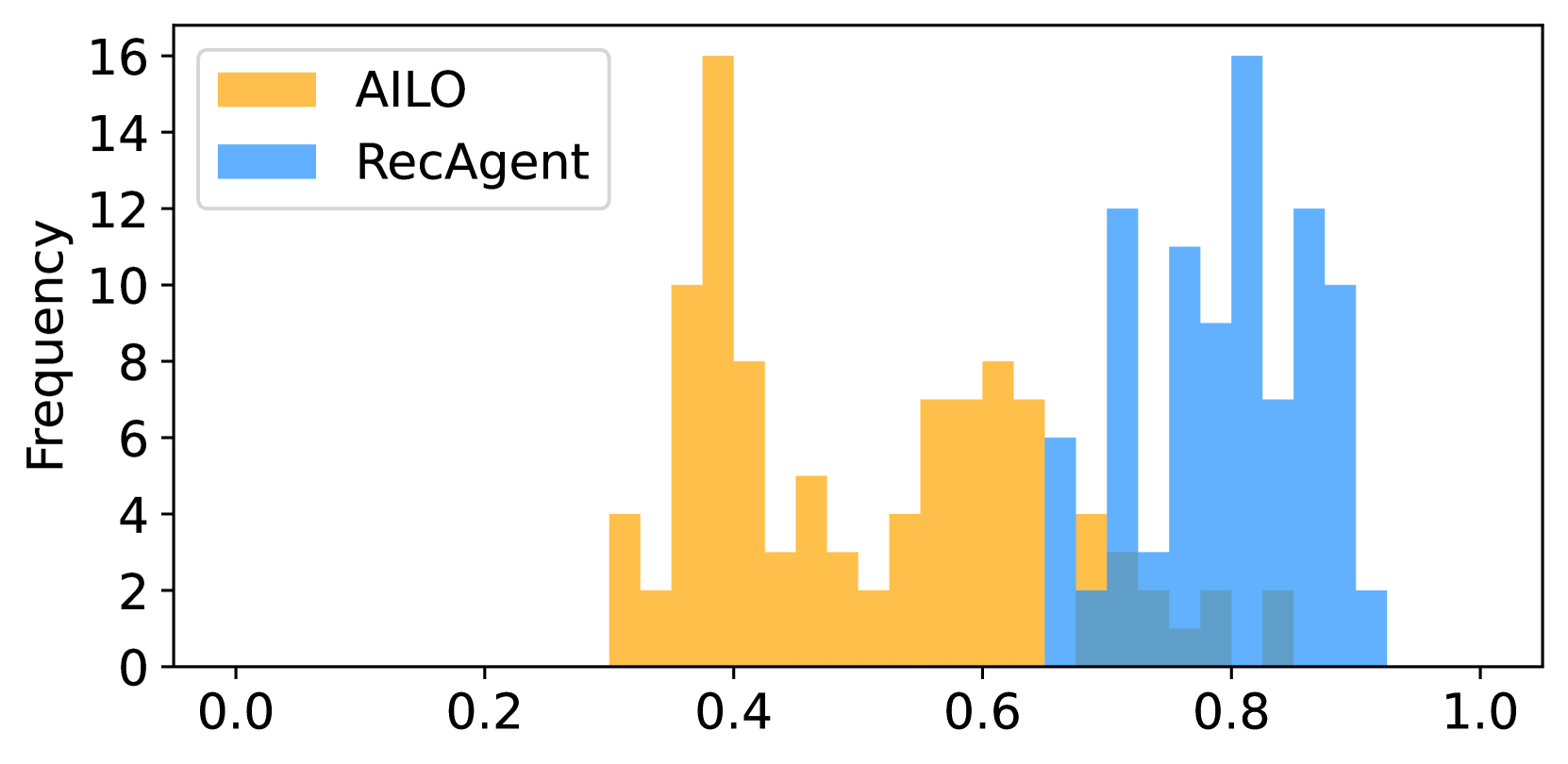
- AILO user simulator generates significantly more diverse user personas (lower ROUGE-L scores) compared to the RecAgent baseline
- AILO achieves a 100% win rate over iEvalLM in human evaluations regarding the human-like quality of simulated dialogue
Breakthrough Assessment
7/10
Novel application of psychological theory (ECT) to eliminate sampling overhead in preference optimization. Strong efficiency gains, though limited by reliance on the quality of the internal simulator.