📝 Paper Summary
Sequential Recommendation
Multimodal Recommendation (Text + ID)
Item Embedding Learning
AlphaFuse learns collaborative ID embeddings within the unused 'null space' of pre-trained language embeddings, preserving rich semantic knowledge while adding behavioral signals without extra parameters.
Core Problem
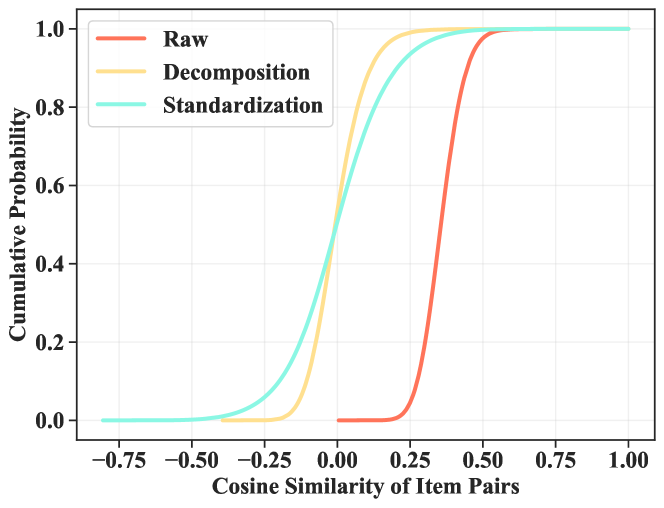
Existing methods for fusing language and ID embeddings suffer from semantic degradation (compressing high-dim semantics into low-dim IDs), underutilization of semantic knowledge, and parameter inefficiency due to auxiliary adapters.
Why it matters:
- LLM-derived embeddings contain rich world knowledge that is often lost when projected down to small ID embedding spaces.
- Auxiliary modules like MLPs or adapters add significant trainable parameters, increasing model complexity and reducing inference efficiency.
- Prior methods either force the behavior space to mimic the semantic space or map semantics to behavior, failing to perfectly preserve the original high-quality semantic information.
Concrete Example:
Mapping a 1536-dimensional OpenAI embedding to a 64-dimensional ID embedding via a trainable adapter causes the semantic space to degenerate into a lower-dimensional manifold, losing fine-grained world knowledge essential for cold-start or long-tail items.
Key Novelty
Null Space Injection for ID Embeddings
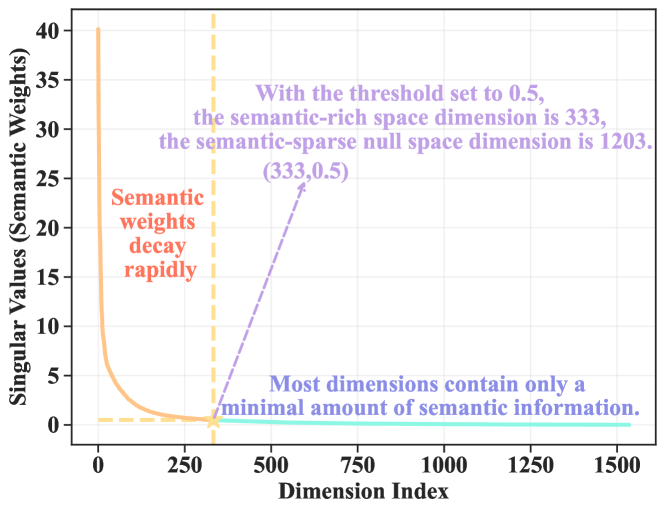
- Decomposes high-dimensional language embeddings via SVD into a 'row space' (semantic-rich) and a 'null space' (semantic-sparse/zero-value).
- Freezes the semantic-rich components to preserve world knowledge and injects trainable ID embeddings specifically into the clipped null space.
- Eliminates the need for external adapters or reconstructors by treating the unused dimensions of the language embedding space as a container for collaborative signals.
Architecture
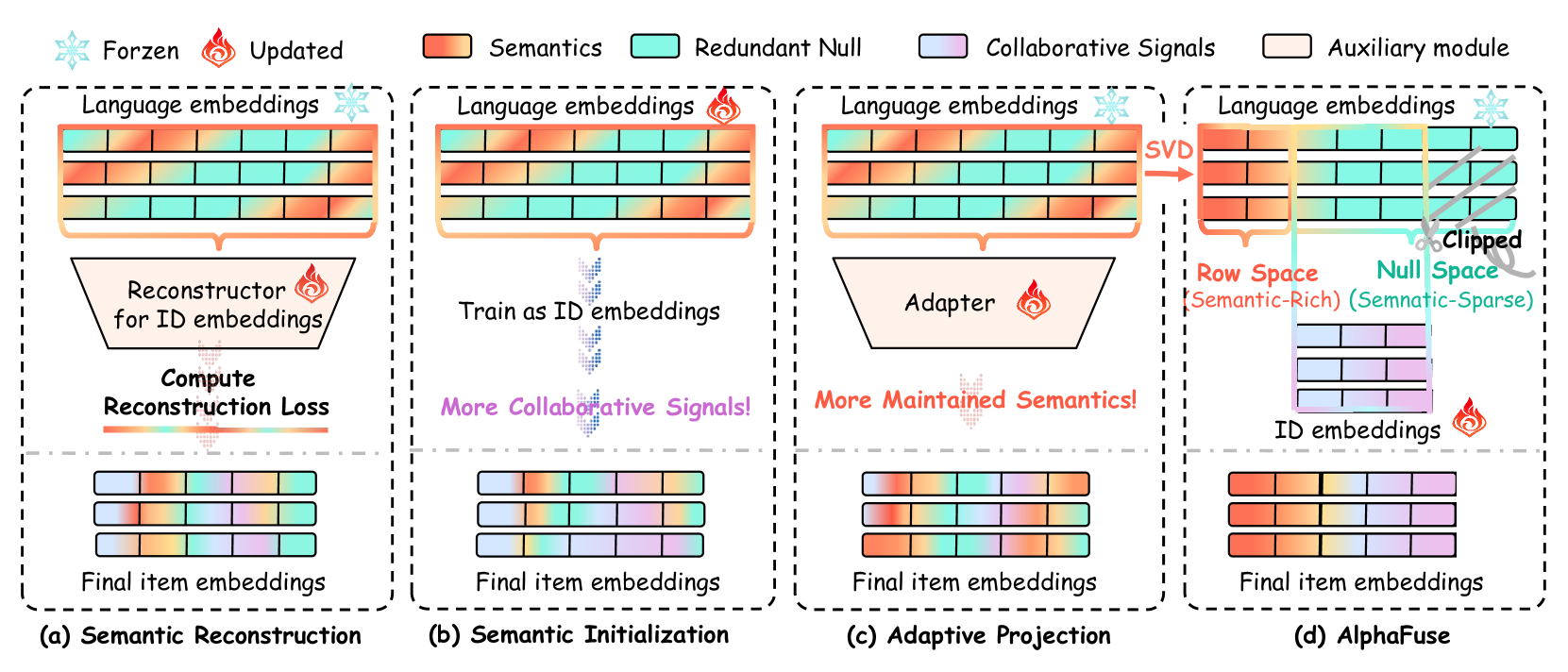
The AlphaFuse pipeline illustrating the decomposition of language embeddings into semantic-rich and null spaces, followed by the injection of ID embeddings.
Evaluation Highlights
- Outperforms state-of-the-art baselines on 3 datasets (Movies, Toys, Sports), achieving the best performance in most metrics.
- Achieves superior performance in cold-start and long-tail settings compared to methods like RECFORMER and KAR.
- Demonstrates high parameter efficiency by removing auxiliary modules (e.g., adapters), relying solely on standard ID embedding parameters.
Breakthrough Assessment
7/10
Offers a mathematically elegant, parameter-free solution to the semantic-collaborative fusion problem. While the performance gains are incremental, the method is highly efficient and model-agnostic.