📝 Paper Summary
LLMs for Recommendation Systems
Benchmark Construction
The paper introduces LRWorld, a benchmark evaluating LLMs in recommendation systems across three scales—association, personalization, and knowledgeability—revealing significant gaps in deep personalized embedding retrieval despite strengths in knowledge reasoning.
Core Problem
There is a large semantic gap between LLMs (internalized language knowledge) and RecSys (personalized behavioral patterns), yet no comprehensive benchmark exists to evaluate LLM limitations across the full spectrum of recommendation tasks.
Why it matters:
- Current research lacks a unified evaluation of LLMs' 'mental models' in recommendation, often focusing narrowly on rating prediction or binary preference
- Understanding whether LLMs can replace traditional models requires testing deep collaborative filtering capabilities (neural embeddings) alongside surface-level reasoning
- Evaluating robustness to noisy profiles and multimodal inputs is critical for real-world deployment
Concrete Example:
When a user watches 'Kill Bill 2', a human mental model connects it to the director Quentin Tarantino (knowledge) and similar action movies (association). While LLMs handle the knowledge part well, they struggle to map the user to a specific point in a deep neural embedding space learned from millions of collaborative interactions, often failing to retrieve the mathematically 'matched' items.
Key Novelty
LRWorld Benchmark Framework
- Conceptualizes the 'mental world' of LLMs in RecSys through three specific scales: Association (rules), Personalization (memory-based and neural matching), and Knowledgeability (KG, taxonomy, multimodal)
- Constructs a diverse dataset (38K samples, 23M tokens) from Amazon, Netflix, and MovieLens, specifically designing tasks to probe deep neural embedding retrieval—a capability rarely tested in LLM benchmarks
Architecture
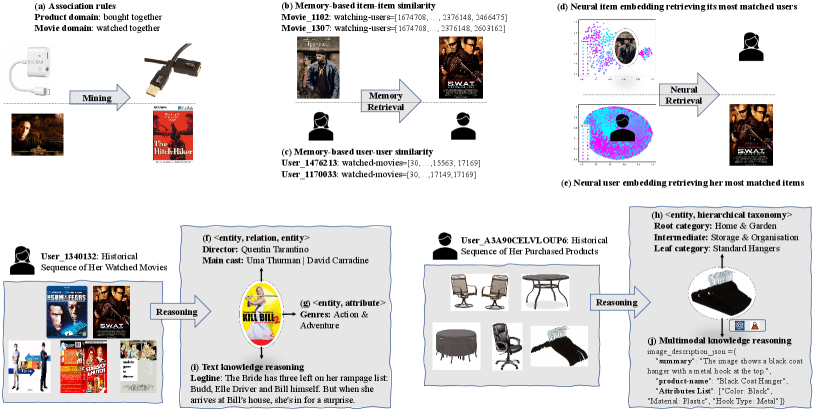
The LRWorld benchmark framework visualizing the 3 scales (Association, Personalization, Knowledgeability) and 10 factors.
Evaluation Highlights
- LLMs excel at association rules (HitRatio@1 of 75%) and entity-relation inference (accuracy 78%), effectively capturing explicit semantic connections
- LLMs perform poorly on deep neural embedding retrieval (HitRatio@1 of only 13%), indicating a failure to internalize high-order collaborative filtering signals
- Model size scaling (e.g., Llama-3-70B vs 8B) yields minimal or negative improvement on neural embedding tasks, suggesting larger models don't automatically solve the personalization gap
Breakthrough Assessment
7/10
Establishes a necessary, comprehensive benchmark revealing the specific weakness of LLMs in deep collaborative filtering, essentially demystifying their 'recommendation' capabilities beyond simple knowledge retrieval.