📝 Paper Summary
Multimodal Search and Recommendation
Small Language Models (SLMs)
Prompt Engineering
A framework for distilling large language model capabilities into a 100M-parameter small language model for efficient multimodal prompt generation using synthetic data and upside-down reinforcement learning.
Core Problem
Large Language Models (LLMs) enable powerful multimodal search and recommendation but incur prohibitive computational and memory costs that hinder deployment in real-time, high-frequency applications.
Why it matters:
- Real-time applications like e-commerce search require low latency (milliseconds) which massive 8B+ models struggle to deliver without expensive hardware
- Deploying full-scale LLMs for every user interaction is resource-intensive and often financially unscalable for high-traffic platforms
- Existing small models often lack the nuanced instruction-following and diversity capabilities required for complex multimodal tasks
Concrete Example:
In a creative design tool, a user might need instant suggestions for 'holiday sale' templates. A standard LLM takes too long and consumes ~80GB memory to generate prompts, whereas this system needs sub-second responses on limited hardware.
Key Novelty
UDRL-Optimized Small Language Model Distillation
- Distills knowledge from a teacher LLM (Llama-3) into a tiny 100M-parameter SLM using a massive synthetic dataset of intent-prompt pairs
- Applies Upside-Down Reinforcement Learning (UDRL) to condition the SLM on desired outcomes (like length and task type) as inputs, rather than just optimizing a reward function directly
Architecture
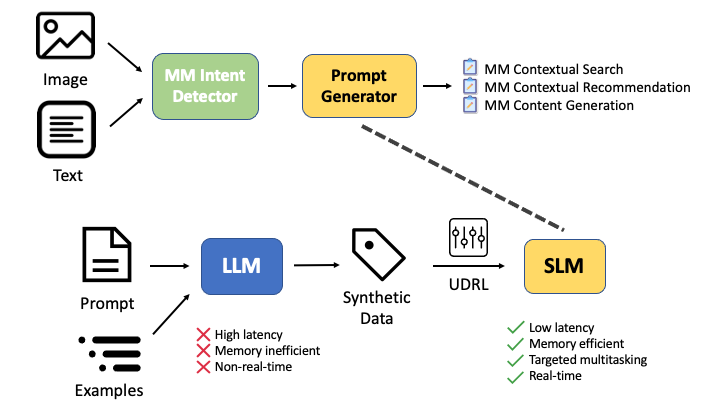
Overview of the multimodal system pipeline: Inputs (Image/Text) -> Intent Detector -> Prompt Generator (SLM) -> Downstream Applications (Search, Recommendation)
Evaluation Highlights
- SLM achieves relevance scores within 6% of Llama-3 8B despite being ~80x smaller (100M vs 8B parameters)
- Inference speed reaches 338 tokens/second on a single A10G GPU, compared to 76–142 tokens/second for 3B–8B baselines
- Memory usage is ~500MB vs ~80GB for baselines, enabling deployment in highly constrained environments
Breakthrough Assessment
7/10
Strong practical contribution demonstrating that huge LLMs are not necessary for specific multimodal tasks; successfully bridges the gap between toy models and deployable engines via UDRL distillation.