📝 Paper Summary
Governance-Constrained Recommendation
Agentic Recommender Systems
AI Safety and Auditing
PCN-Rec ensures recommender systems strictly obey governance policies by using a multi-agent negotiation process to propose rankings and a deterministic code-based verifier to reject and repair violations.
Core Problem
Monolithic LLM recommenders struggle to reliably satisfy hard combinatorial constraints (like diversity quotas) and lack auditability, often generating plausible text explanations while violating policies.
Why it matters:
- Platforms face legal or contractual obligations (e.g., minimum long-tail exposure) that must be strictly enforced and auditable
- LLMs suffer from 'lost-in-the-middle' reasoning and cannot maintain global state over combinatorial constraints, leading to silent failures
- Existing methods lack a mechanism to prove that a served slate actually met the required policy checks
Concrete Example:
A platform requires every movie recommendation list to have at least 30% 'long-tail' (unpopular) items. A standard LLM might generate a list of 10 blockbusters and hallucinate a justification claiming it is diverse. PCN-Rec's verifier would catch the metadata mismatch (0% tail) and force a repair.
Key Novelty
Proof-Carrying Negotiation (PCN)
- Treats the LLM as a 'proposer' rather than an authority; it must output a structured certificate (JSON) proving compliance alongside its recommendation
- Splits the recommendation task into specialized agents: a User Advocate (optimizing relevance) and a Policy Agent (enforcing constraints) to negotiate trade-offs
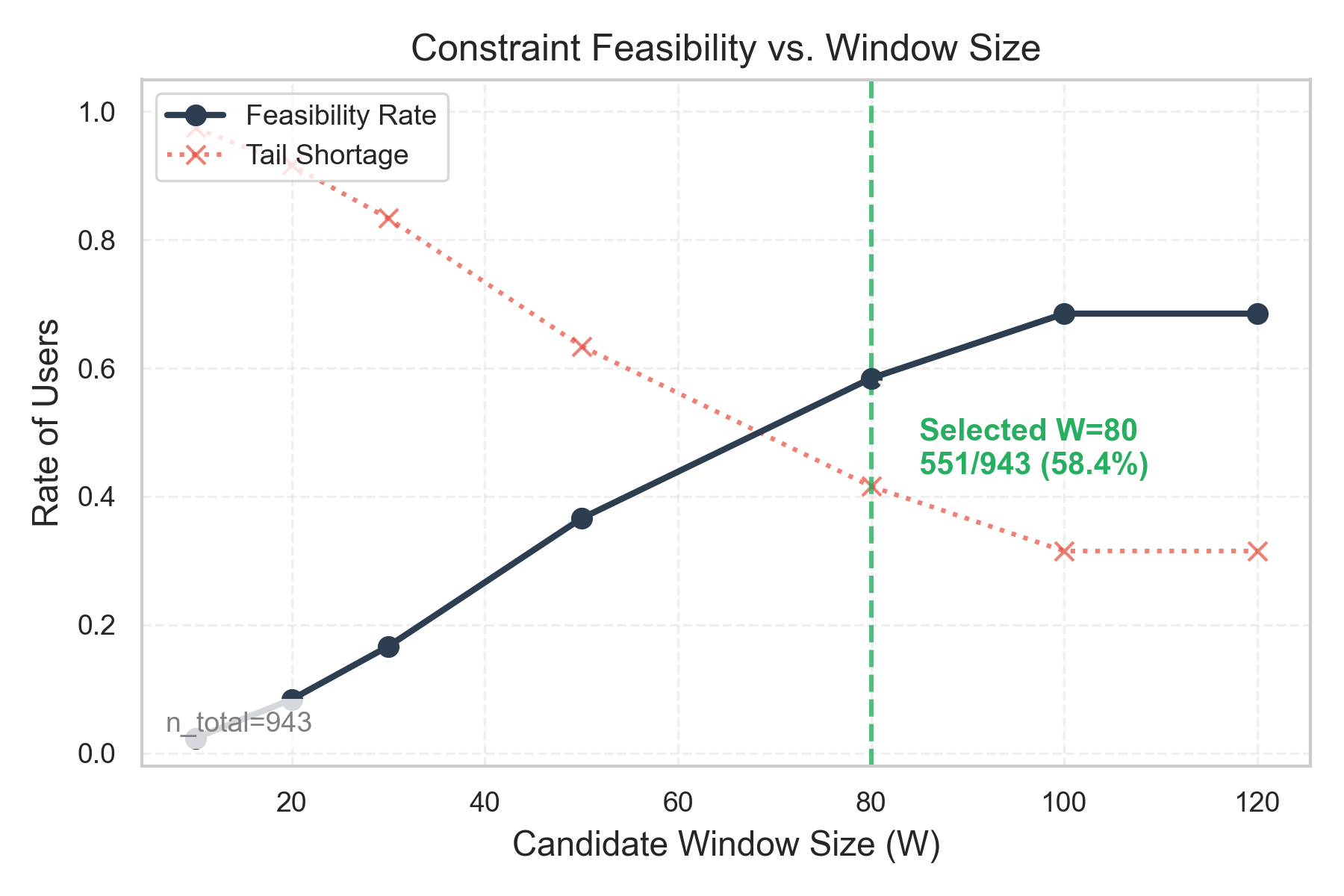
- Introduces a window-based feasibility analysis to distinguish between 'impossible to satisfy' user histories and 'AI failure' cases
Architecture
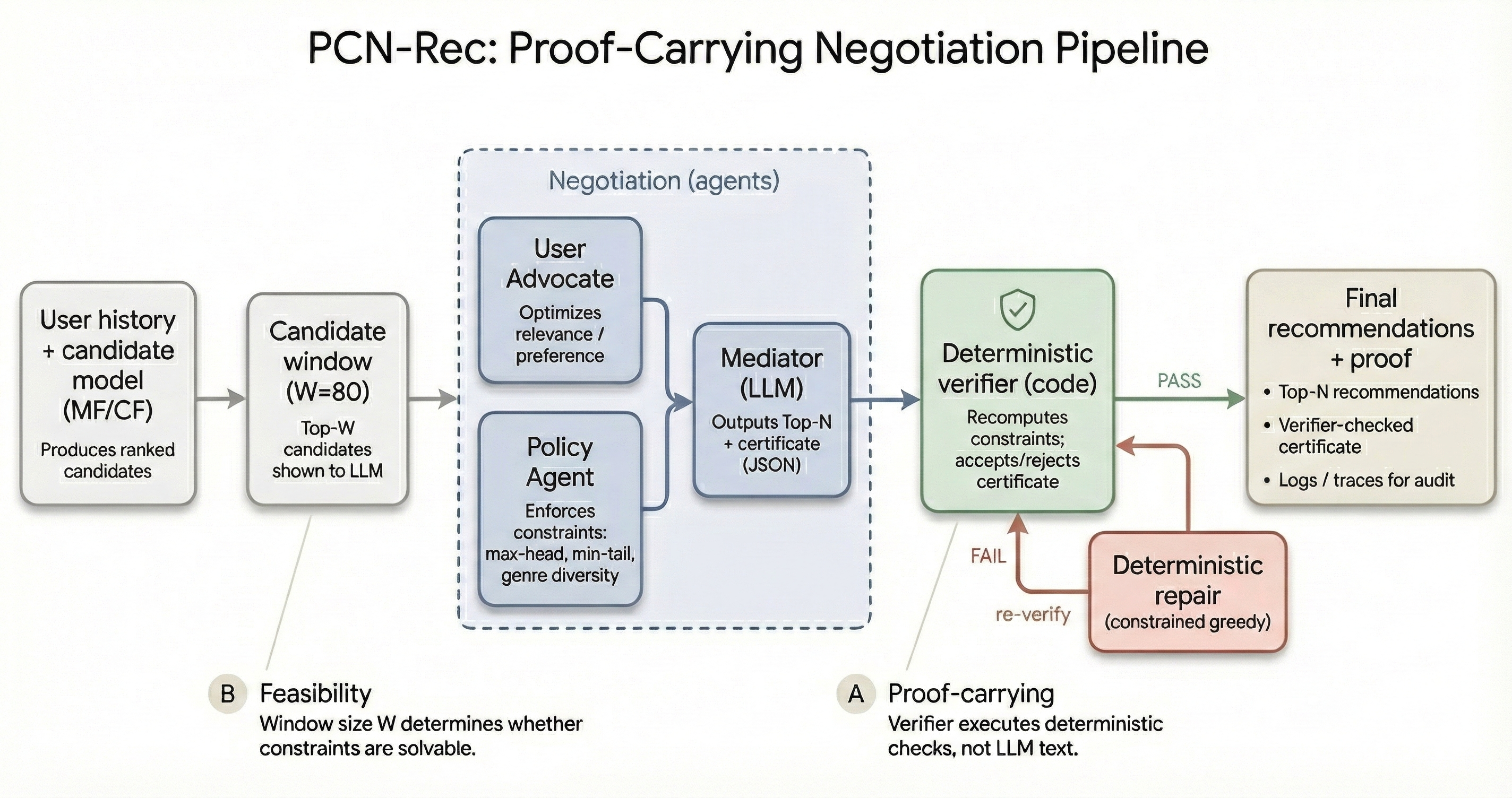
The PCN-Rec pipeline separating the Base Recommender, the Agentic Negotiation (User Advocate vs Policy Agent), the Mediator, and the Deterministic Verifier/Repair loop.
Evaluation Highlights
- Achieves 98.55% governance pass rate on feasible users in MovieLens-100K, compared to 0.00% for a single-LLM baseline
- Maintains utility with only a 0.021 absolute drop in NDCG@10 (0.403 vs. 0.424) compared to an unconstrained LLM, a statistically significant but minimal cost for safety
- Identifies that 551 out of 943 users (58%) have feasible solutions within a candidate window of 80 items, validating the feasibility-aware evaluation protocol
Breakthrough Assessment
8/10
Significantly advances reliable GenAI deployment by solving the 'silent violation' problem in regulated recommendation. The proof-carrying interface provides a practical blueprint for auditable AI.