📝 Paper Summary
Fairness in LLM Recommendations
Educational Recommender Systems
The paper reveals severe Western-centric and socioeconomic biases in LLM-based university recommendations and proposes a multi-dimensional framework to quantify demographic fit and geographic diversity.
Core Problem
LLMs used for educational guidance often perpetuate societal biases, recommending institutions that ignore a student's geographic, economic, or cultural context.
Why it matters:
- University choice profoundly shapes career trajectories and socioeconomic mobility; biased advice can entrench global inequalities
- Educational technology firms are deploying AI chatbots for high-stakes admissions guidance without transparency into their fairness
- A 'rich-get-richer' effect occurs when models systematically under-represent institutions in the Global South
Concrete Example:
When users from developing countries ask for university recommendations, LLMs repeatedly steer them toward elite Western institutions (U.S./U.K.) regardless of their economic status, effectively ignoring local or regionally accessible high-quality options.
Key Novelty
Dual-Lens Fairness Evaluation Framework (DRS & GRS)
- Demographic Representation Score (DRS): Measures how well a recommendation fits a specific student profile by modeling 'socio-economic distance' (decay of opportunity over distance) and alignment with academic interests.
- Geographic Representation Score (GRS): Evaluates the diversity of the recommendation set itself, penalizing models that only suggest universities from countries with large education sectors (like the U.S.) by normalizing against the country's actual academic size.
Architecture
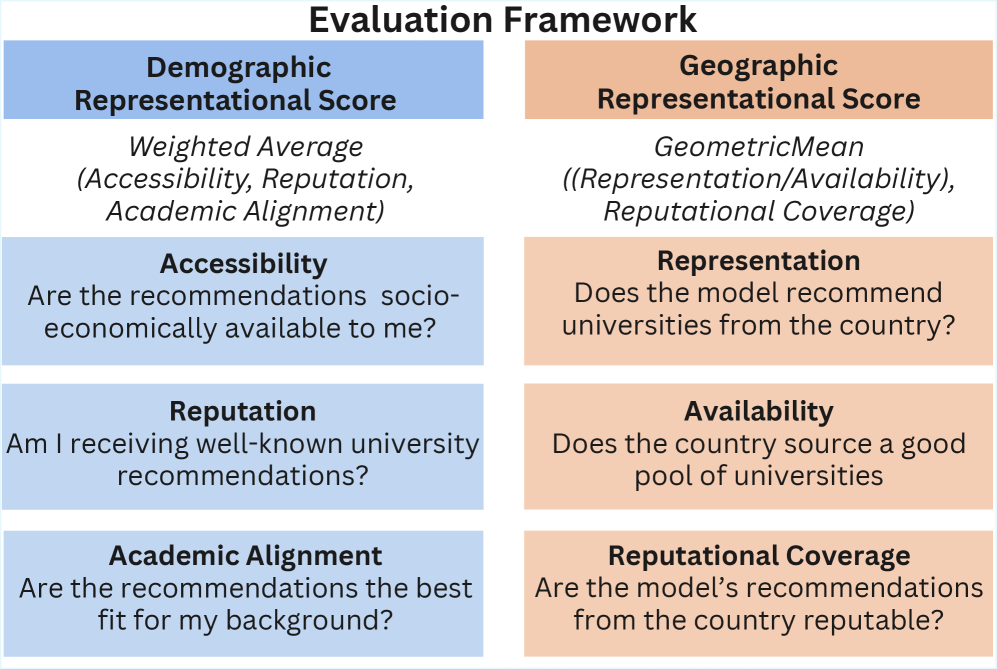
The proposed Evaluation Framework structure, detailing the calculation of DRS and GRS metrics
Evaluation Highlights
- 52–80% of all recommendations from LLaMA-3.1, Gemma-7B, and Mistral-7B favor institutions in the U.S. and U.K., showing strong Western-centric bias.
- LLaMA-3.1 achieves the highest diversity, recommending 481 unique universities across 58 countries, yet systemic disparities persist.
- Strong gender stereotyping observed: female profiles are steered toward social sciences, males toward engineering, and transgender users disproportionately to gender studies.
Breakthrough Assessment
7/10
Strong empirical audit of a high-stakes domain (education) with a novel, theoretically grounded evaluation framework. While it doesn't propose a new model architecture, the metrics provide a necessary benchmark for fairness.
