📝 Paper Summary
Generative Recommendation (GR)
Efficient LLM Inference
Speculative Decoding
NEZHA accelerates generative recommendation by integrating a self-drafting head into the main model and using a hash-based verifier to reject invalid item IDs without extra model calls.
Core Problem
Generative Recommendation (GR) suffers from high inference latency due to autoregressive decoding, making it unfeasible for real-time industrial applications like search advertising.
Why it matters:
- In latency-sensitive scenarios like Taobao search ads (serving hundreds of millions of users), response times must be under 30ms, while standard GR solutions exceed 1 second
- Decoding accounts for over 60% of total inference time, creating a bottleneck that KV-caching alone cannot solve
- Existing Speculative Decoding methods require external draft models (maintenance overhead) or verify with large model calls (limiting speedup)
Concrete Example:
In a standard setup with a beam size of 512, an LLM must be invoked hundreds of times to generate a 3-token item ID. Current methods might draft tokens quickly but then waste time verifying them by running the large model again, still failing the strict 30ms requirement.
Key Novelty
NEZHA (Nimble Drafting and Efficient Verification)
- Self-drafting via special placeholders: The model uses special input tokens to pre-compute hidden states in a single pass, allowing a lightweight internal head to predict future tokens without a separate draft model
- Model-free verification: Exploits the structured nature of semantic IDs (where valid combinations are sparse) to verify candidates using a simple hash set lookup instead of an expensive LLM forward pass
Architecture
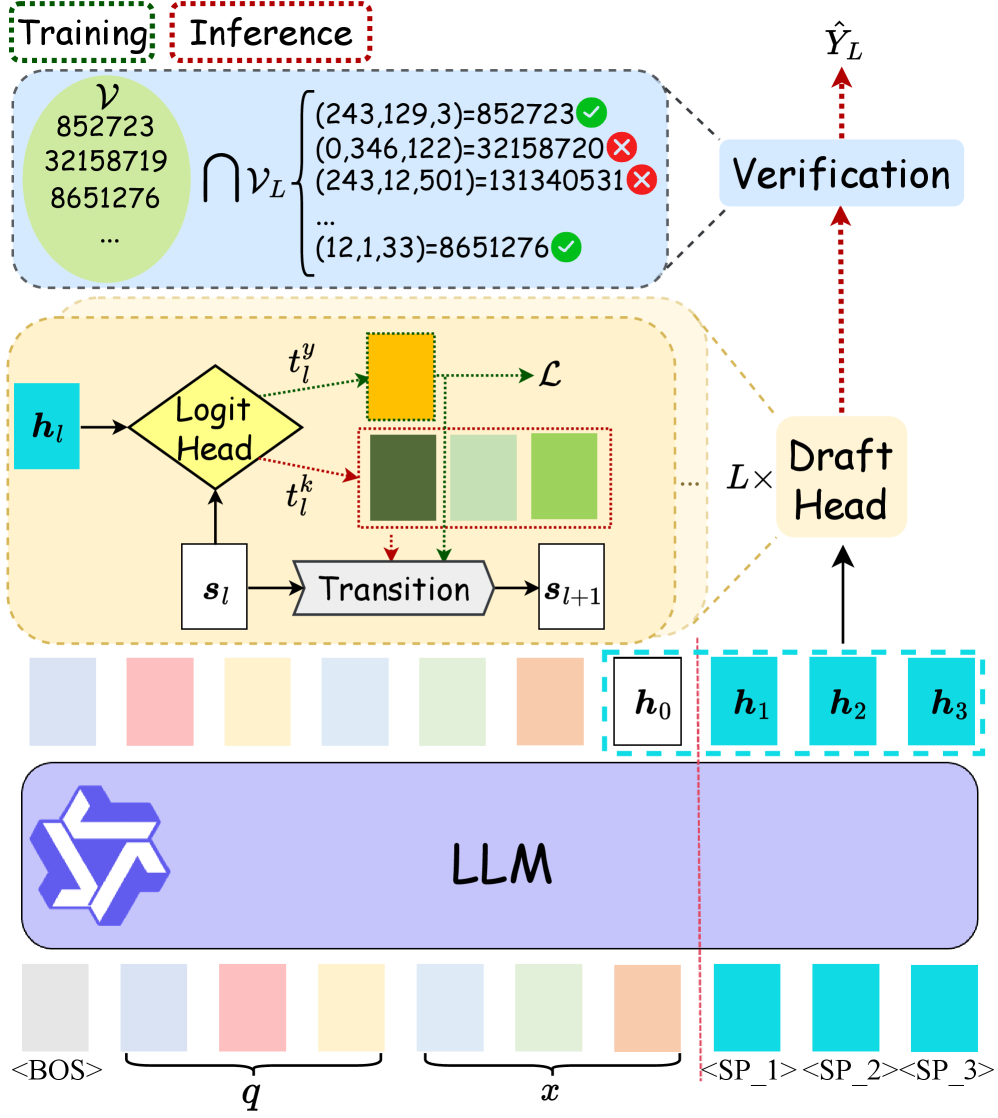
The NEZHA framework comparing standard autoregressive decoding with its self-drafting + verification approach.
Evaluation Highlights
- Achieved 1.2% business improvement (billion-level revenue increase) after deployment on Taobao
- Reduced decoding latency by ~4-8x compared to standard Beam Search on public datasets (e.g., 2.75ms vs 22.81ms on Amazon-Beauty)
- Improved Recall@10 by +12% absolute (from ~43% to ~55%) compared to standard speculative decoding by filtering hallucinations
Breakthrough Assessment
9/10
Solving the inference latency bottleneck for Generative Recommendation is a critical industrial blocker. Successfully deploying this to hundreds of millions of users with significant revenue gains demonstrates immense practical value.