📝 Paper Summary
Session-based Recommendation (SR)
Intent-aware Recommendation
LLM Prompt Optimization
PO4ISR automates prompt optimization for session-based recommendation by using LLMs to self-reflect on error cases, refine prompts iteratively, and transfer the best prompts across domains.
Core Problem
Traditional intent-aware session recommendation methods assume a fixed number of latent intents and lack transparency, while existing LLM approaches rely on static prompts that fail to capture dynamic user intents.
Why it matters:
- Real-world sessions have varying, dynamic intents (e.g., buying a laptop vs. buying multiple unrelated gifts) that fixed-intent models miss
- Latent embedding spaces in traditional models are opaque, making recommendations hard to explain or interpret
- Manually designing optimal prompts for LLMs is tedious and often suboptimal compared to automated refinement
Concrete Example:
A user buys a laptop, then a camera. A standard model might assume a single 'electronics' intent. PO4ISR's prompt explicitly instructs the LLM to identify multiple intents (laptop accessories vs. camera accessories) and rank the next item (a camera lens) higher than a laptop bag.
Key Novelty
Prompt Optimization for Intent-aware Session Recommendation (PO4ISR)
- Iteratively optimizes prompts by asking the LLM to analyze its own recommendation errors, infer reasons for failure, and rewrite the prompt to address those specific weaknesses
- Evaluates prompt candidates using a UCB (Upper Confidence Bound) bandit algorithm to efficiently identify high-performing prompts without testing every prompt on the full dataset
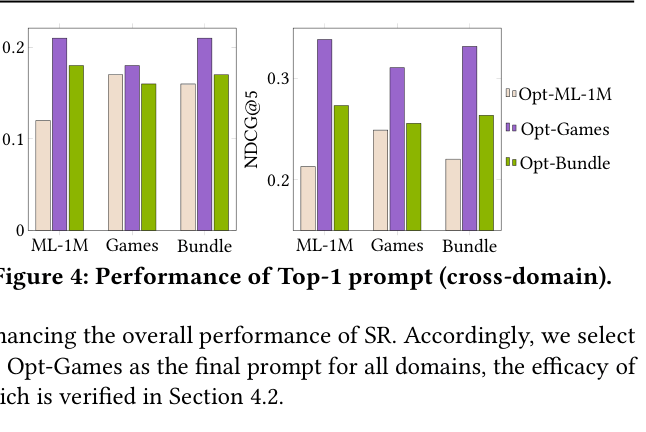
- Leverages cross-domain transfer by selecting the best-performing prompt from a source domain (e.g., Games) to use in target domains, exploiting LLM generalizability
Architecture
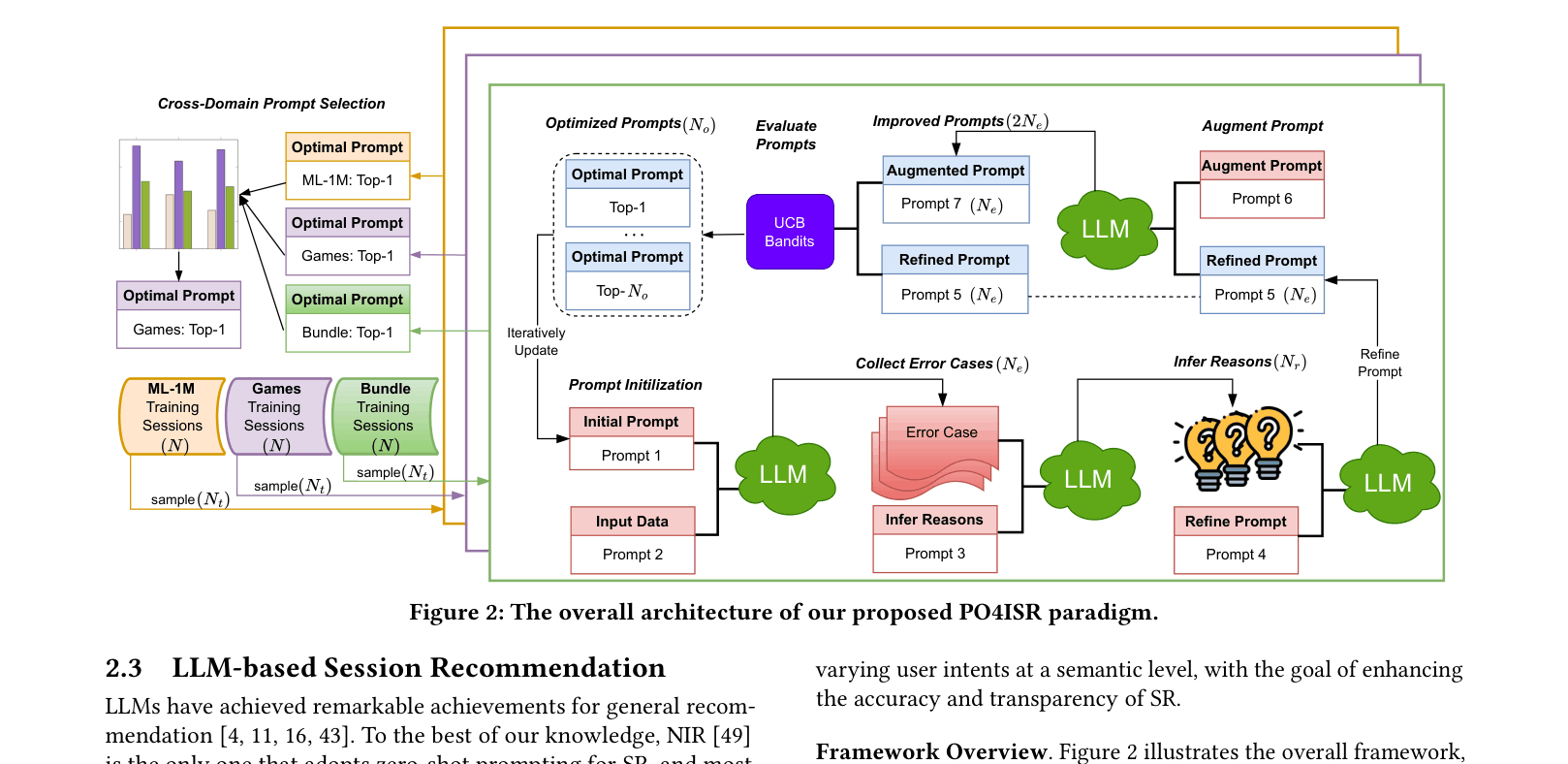
The overall PO4ISR pipeline including initialization, the optimization loop (error collection -> reasoning -> refinement -> evaluation), and selection.
Evaluation Highlights
- +57.37% average improvement in HR@5 and +61.03% in NDCG@5 over state-of-the-art baselines across three datasets
- Outperforms standard zero-shot prompting (NIR) by ~121% on Games dataset (NDCG@1), proving the value of iterative optimization over static prompts
- Cross-domain prompt selection works effectively: The prompt optimized on the Games dataset achieved the best performance even when applied to the Movie and Bundle domains
Breakthrough Assessment
7/10
Significant performance jumps over non-LLM baselines and static prompting. The application of automatic prompt optimization (APO) to recommendation is novel and practical, though the core mechanism borrows from NLP optimization techniques.