📝 Paper Summary
Session-based Recommendation (SBR)
Knowledge Distillation (KD)
Large Language Models (LLMs)
ALKDRec improves recommendation efficiency by using active learning to select only the most informative subset of user sessions for distilling knowledge from an LLM teacher to a lightweight student.
Core Problem
Distilling knowledge from LLMs for recommendation is computationally expensive if done on all data, and LLMs often produce ineffective (incorrect or trivial) predictions that harm student training.
Why it matters:
- Deploying LLMs directly for recommendation is too slow and memory-intensive for real-time applications like on-device session-based recommendation
- Existing Knowledge Distillation methods require expensive LLM inference on the entire dataset, which is not sustainable
- Indiscriminate distillation transfers noise from incorrect LLM predictions or redundant information from easy instances, reducing student performance
Concrete Example:
If a user session is very 'easy' (standard behavior), the LLM predicts the same as a small model, providing zero gain (redundant). If a session is 'hard' (noisy behavior), the LLM might hallucinate a wrong item, providing negative gain. Standard KD trains on both, wasting compute and confusing the student.
Key Novelty
Active Learning for Knowledge Distillation in Recommendation (ALKDRec)
- Enhances the LLM teacher by prompting it to 'summarize' patterns from a conventional recommender's output before making its own predictions
- Categorizes training instances into three types: Effective (high gain), Similar (redundant), and Incorrect (negative gain) based on difficulty and model consistency
- Selects a small subset of instances for distillation by maximizing the 'minimal expected gain,' theoretically ensuring informative samples are chosen while avoiding noise
Architecture
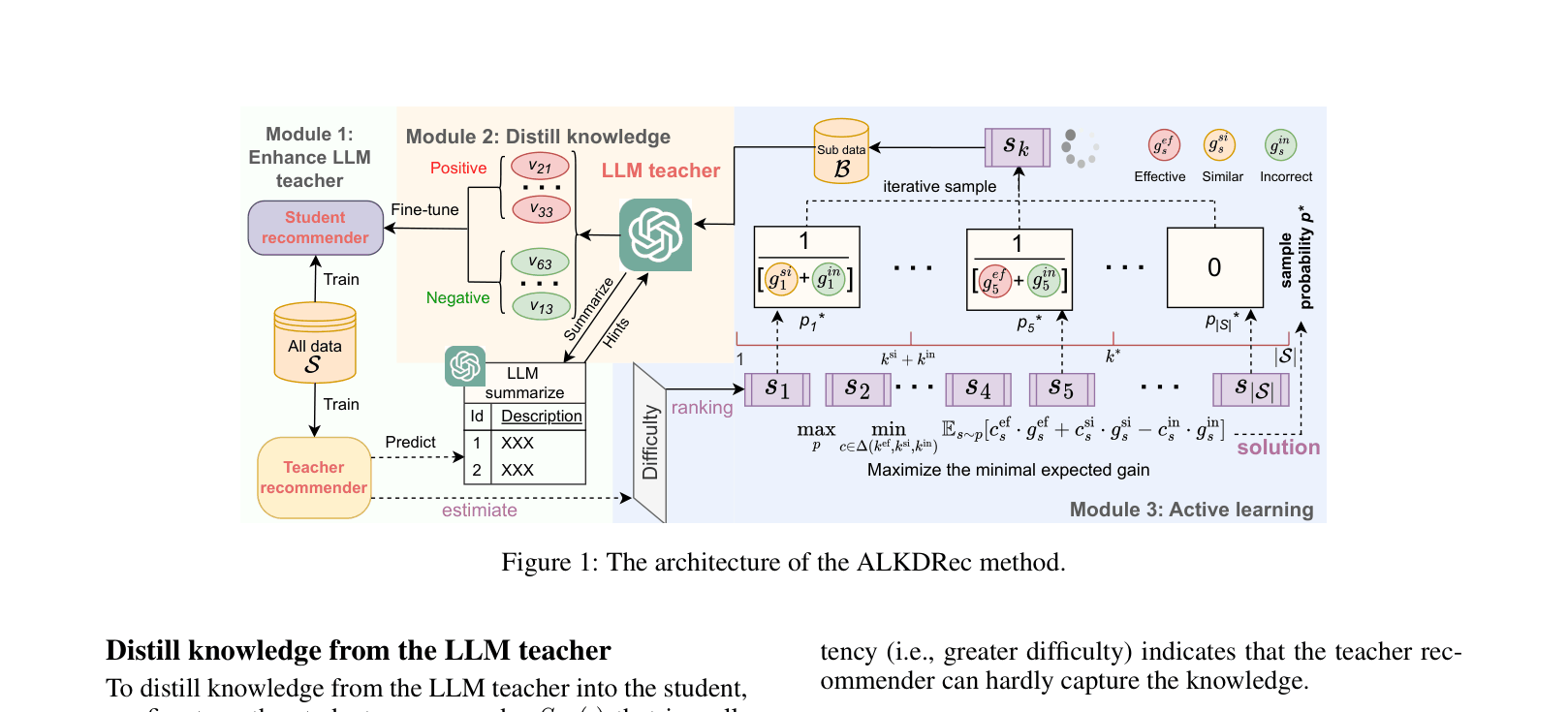
The ALKDRec workflow: Hint generation, Active Selection, and Distillation.
Evaluation Highlights
- Outperforms state-of-the-art KD methods by up to 34.78% (Recall@5) on Hetrec2011-ML using the FPMC backbone
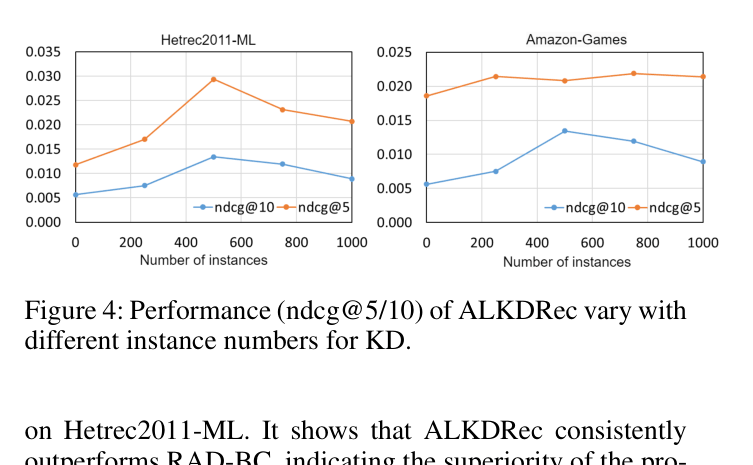
- Achieves superior performance using only ~500 instances for LLM distillation, compared to baselines distilling from the full dataset (12k-20k sessions)
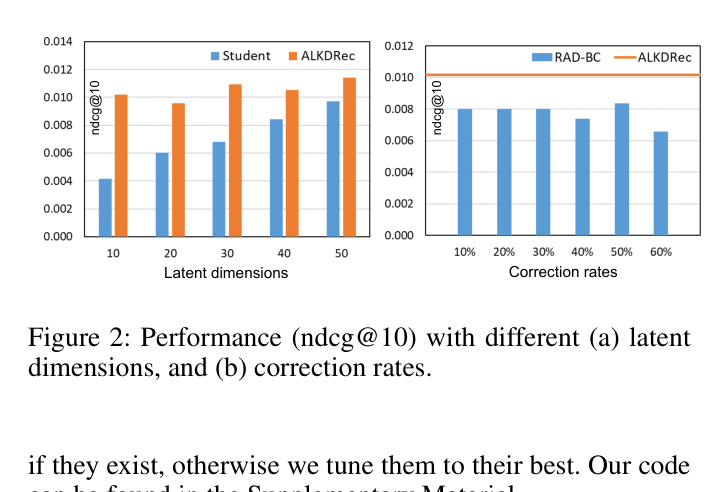
- Surpasses the teacher recommender itself in accuracy despite having a model size 10x smaller, demonstrating effective knowledge transfer
Breakthrough Assessment
7/10
Solid contribution applying active learning to LLM distillation. Addresses the critical cost bottleneck of LLM-based KD. Theoretical bounding of expected gain is a nice addition to the empirical results.