📝 Paper Summary
Content-based Recommendation
News Recommendation
Book Recommendation
SPAR efficiently extracts user interests from long engagement histories by combining session-based language model encoding with sparse attention mechanisms and global summaries generated by large language models.
Core Problem
Pretrained Language Models (PLMs) struggle to process very long user engagement histories (often >5K tokens) due to quadratic attention complexity and token limits, leading to loss of fine-grained interest signals.
Why it matters:
- Platforms like Google News or Reddit generate massive user histories that exceed standard model capacities, forcing systems to truncate data or lose cross-item context
- Existing methods that encode items separately and average them fail to capture the complex, sequential evolution of user interests
- Effective personalization requires maintaining standalone user/item embeddings for efficient retrieval while still capturing deep semantic interactions
Concrete Example:
A user's history might contain 50 news articles (approx. 5K tokens). A standard BERT model (512 token limit) must either truncate 90% of the history or encode each article in isolation, missing the connection between a tech article read yesterday and a related financial article read today.
Key Novelty
Post-fusion with Sparse Poly-Attention for Recommendation (SPAR)
- Encodes user history in sessions using a PLM to handle length, then aggregates them using a 'poly-attention' mechanism that projects thousands of tokens into a compact set of interest vectors
- Applies strict sparsity rules (local window, global landmarks, random sampling) to the attention mechanism, allowing the model to attend to very long sequences without memory overflow or entropy collapse
- Augments the raw history with a natural language summary of the user's global interests generated by an LLM (Llama-2), providing a high-level semantic anchor
Architecture
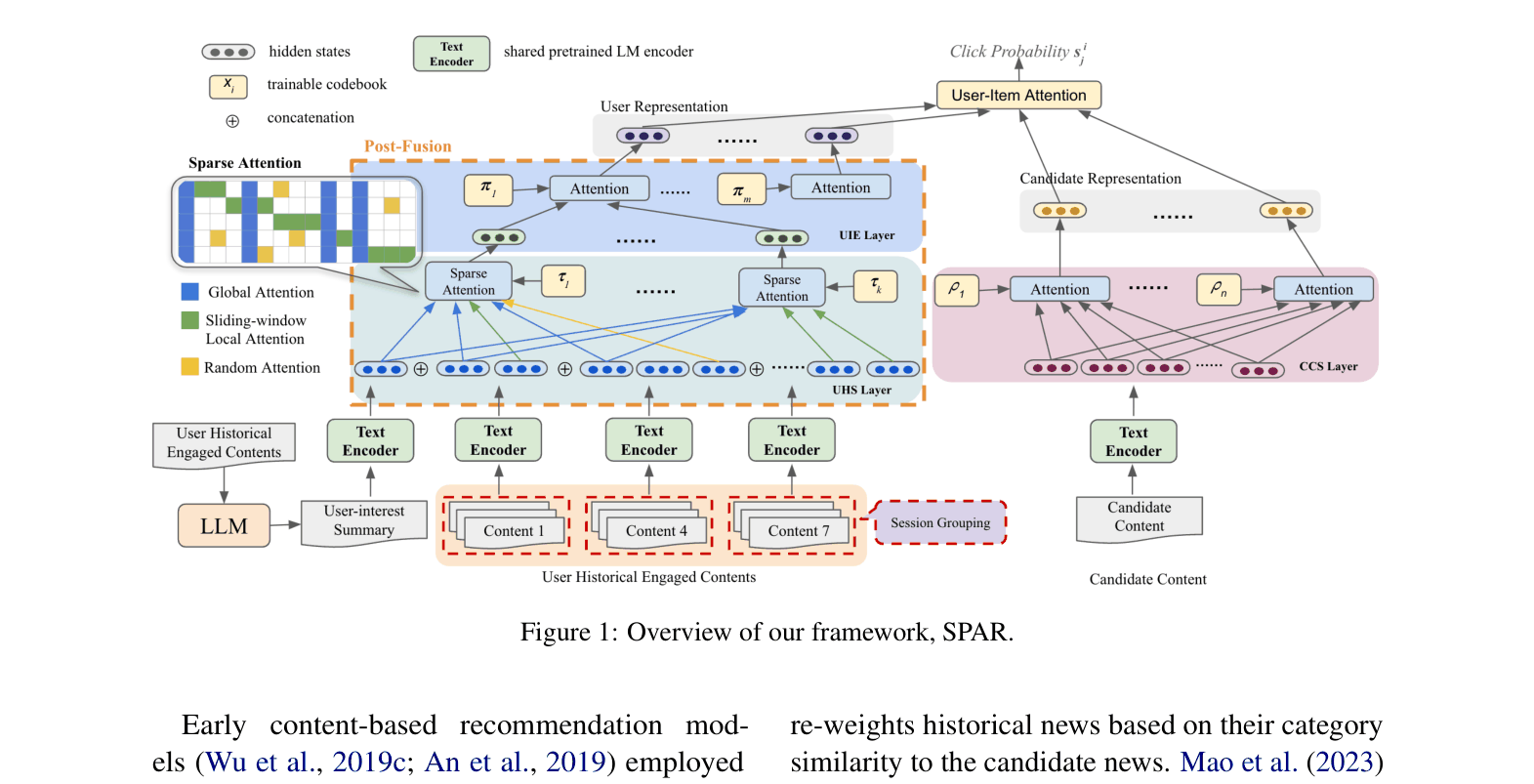
Overview of the SPAR framework showing the data flow from user history texts to final relevance score.
Evaluation Highlights
- Outperforms SOTA method UNBERT by +1.48 AUC on the MIND news recommendation dataset
- Achieves +1.15 AUC improvement over UNBERT on the Goodreads book recommendation dataset
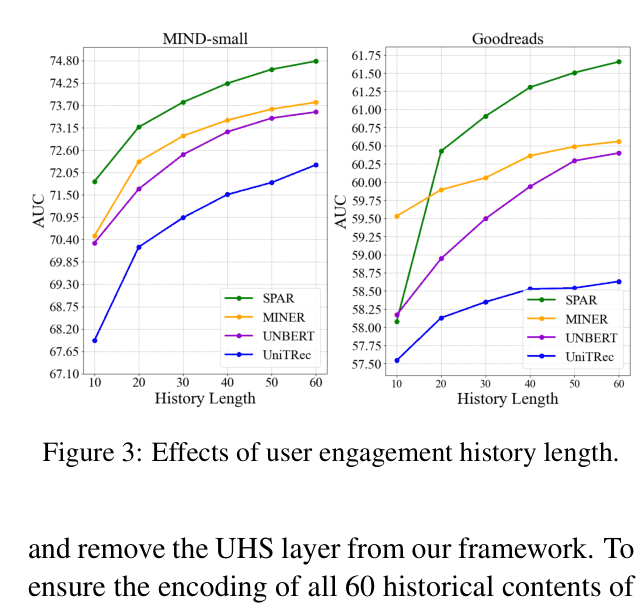
- Maintains superior performance even as user history length increases to 60 items, whereas baselines like MINER and UNBERT plateau or degrade
Breakthrough Assessment
7/10
Solid architectural advancement solving the specific 'long context' problem in content recommendation. Effectively combines modern LLM summarization with efficient attention mechanisms to beat strong PLM baselines.