📊 Experiments & Results
Evaluation Setup
Offline evaluation on held-out user-title pairs from Netflix logs
Benchmarks:
- Netflix Internal Dataset (Personalized Artwork Selection) [New]
Metrics:
- Inverse Propensity Score (IPS)
- Accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Main results comparing post-trained LLMs against the Netflix Production Model baseline. | ||||
| Netflix Internal Dataset | IPS (Inverse Propensity Score) | 0.00 | 0.05 | +0.05 |
| Netflix Internal Dataset | IPS (Inverse Propensity Score) | 0.00 | 0.03 | +0.03 |
| Ablation on output format showing sensitivity to text vs integer outputs. | ||||
| Netflix Internal Dataset | Accuracy | 0.224 | 0.244 | +0.020 |
| Netflix Internal Dataset | Accuracy | 0.334 | 0.456 | +0.122 |
Experiment Figures
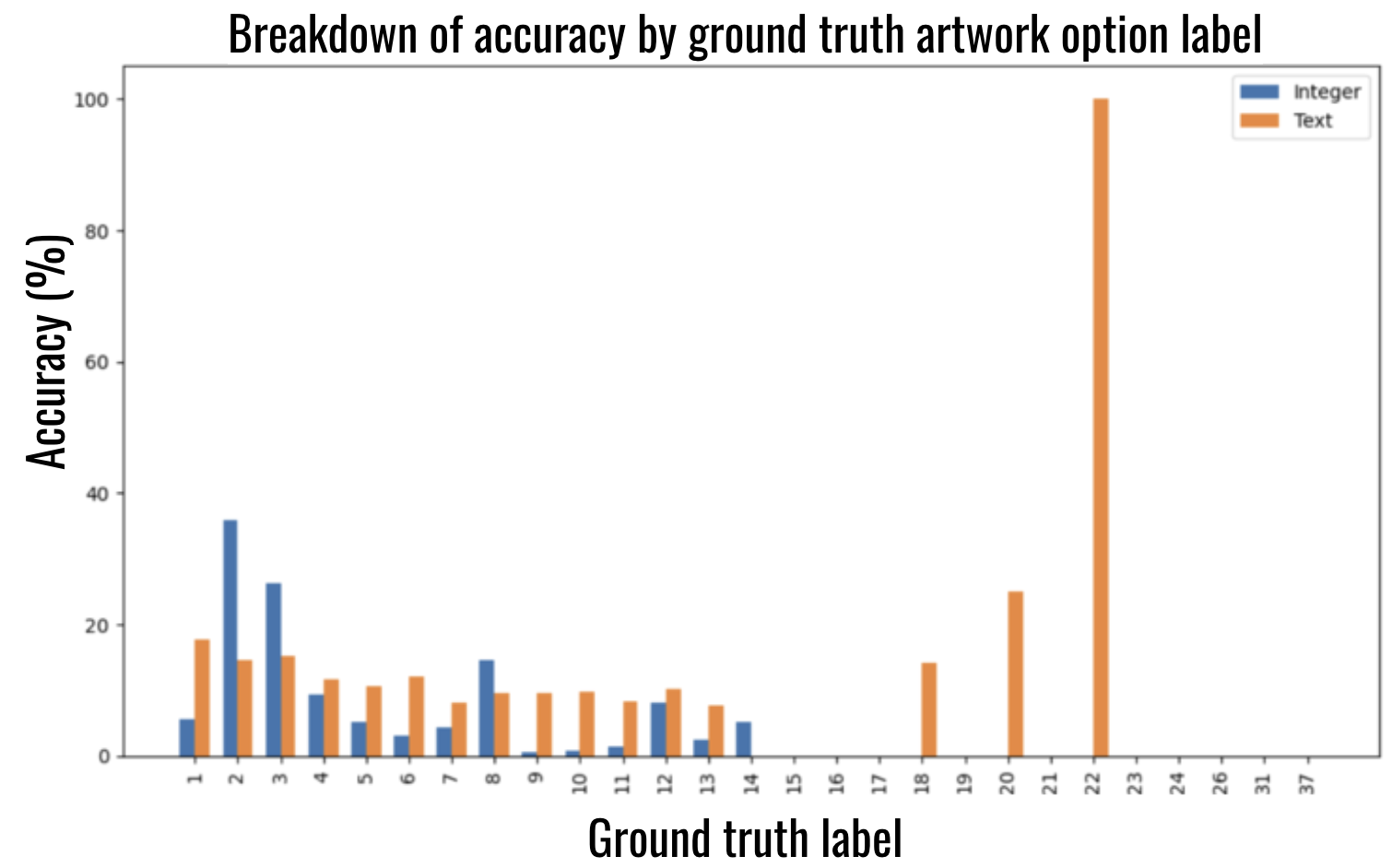
Breakdown of model accuracy across different ground truth labels (artwork indices) for the 3B model.
Main Takeaways
- Post-trained LLMs outperform production baselines, suggesting LLMs capture nuanced user preferences better than traditional models.
- Reasoning distillation (teaching the model 'why' an artwork is good) yields the highest performance gains (+5%).
- Model size matters for output formatting: smaller models (3B) bias toward small integers, while larger models (8B) handle text outputs more effectively.
- Zero-shot performance is surprisingly strong, indicating pre-trained LLMs already possess relevant world knowledge for personalization.