📊 Experiments & Results
Evaluation Setup
Interactive recommendation on AgentRecBench
Benchmarks:
- Amazon (Product Recommendation)
- Yelp (Business Recommendation)
- Goodreads (Book Recommendation)
Metrics:
- Avg HR@1,3,5 (Hit Rate)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| ChainRec consistently outperforms baselines on Hit Rate metrics across multiple domains. | ||||
| Amazon/Yelp/Goodreads | Avg HR@{1,3,5} | Not reported in the paper | Not reported in the paper | Not reported in the paper |
Experiment Figures

Three representative examples (Sample 1-3) showing the model following different reasoning routes (focusing on different evidence) for the same prompt but different scenarios.
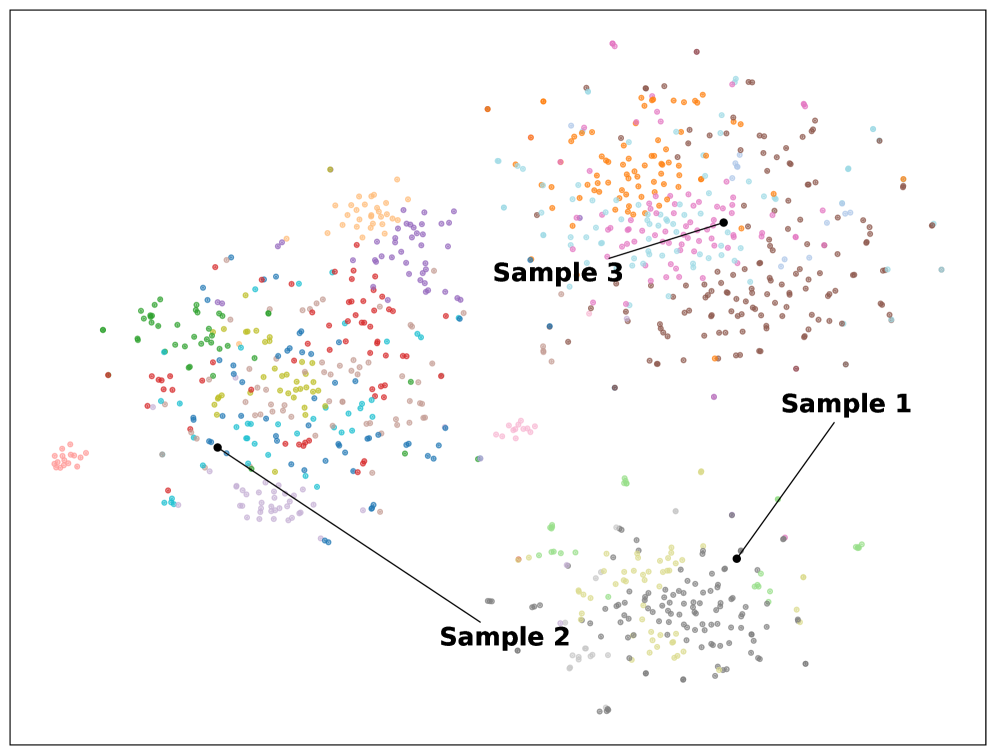
Visualization of embedded reasoning traces at scale, showing they form multiple distinct clusters.
Main Takeaways
- ChainRec consistently improves Hit Rate over strong baselines across Amazon, Yelp, and Goodreads.
- Gains are most notable in 'cold-start' and 'evolving-interest' scenarios, validating the benefit of dynamic planning.
- Ablation studies confirm the necessity of both the Standardized Tool Library (TAL) and the DPO-optimized planner; removing either degrades performance.