📊 Experiments & Results
Evaluation Setup
Zero-shot prompting with increasing context length (list size) on synthetic and real datasets
Benchmarks:
- Numbers (Synthetic Missing Item) [New]
- Numbers-English (Synthetic Missing Item (Word form)) [New]
- Movies (MovieLens 1M) (Recommendation / History Completion) [New]
Metrics:
- Accuracy (Predicting the exact missing item y)
- Repetition Rate (Predicting an item already in X)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Zero-shot performance results showing the degradation of Llama-3-8B-Instruct as the input list size increases. | ||||
| Numbers | Repetition Rate | 0.00 | 0.85 | +0.85 |
| Numbers | Accuracy | 1.00 | 0.00 | -1.00 |
| Numbers (1024 items) | Accuracy | 0.75 | 0.00 | -0.75 |
| Numbers (512 items) | Accuracy | 0.05 | 0.05 | +0.00 |
Experiment Figures
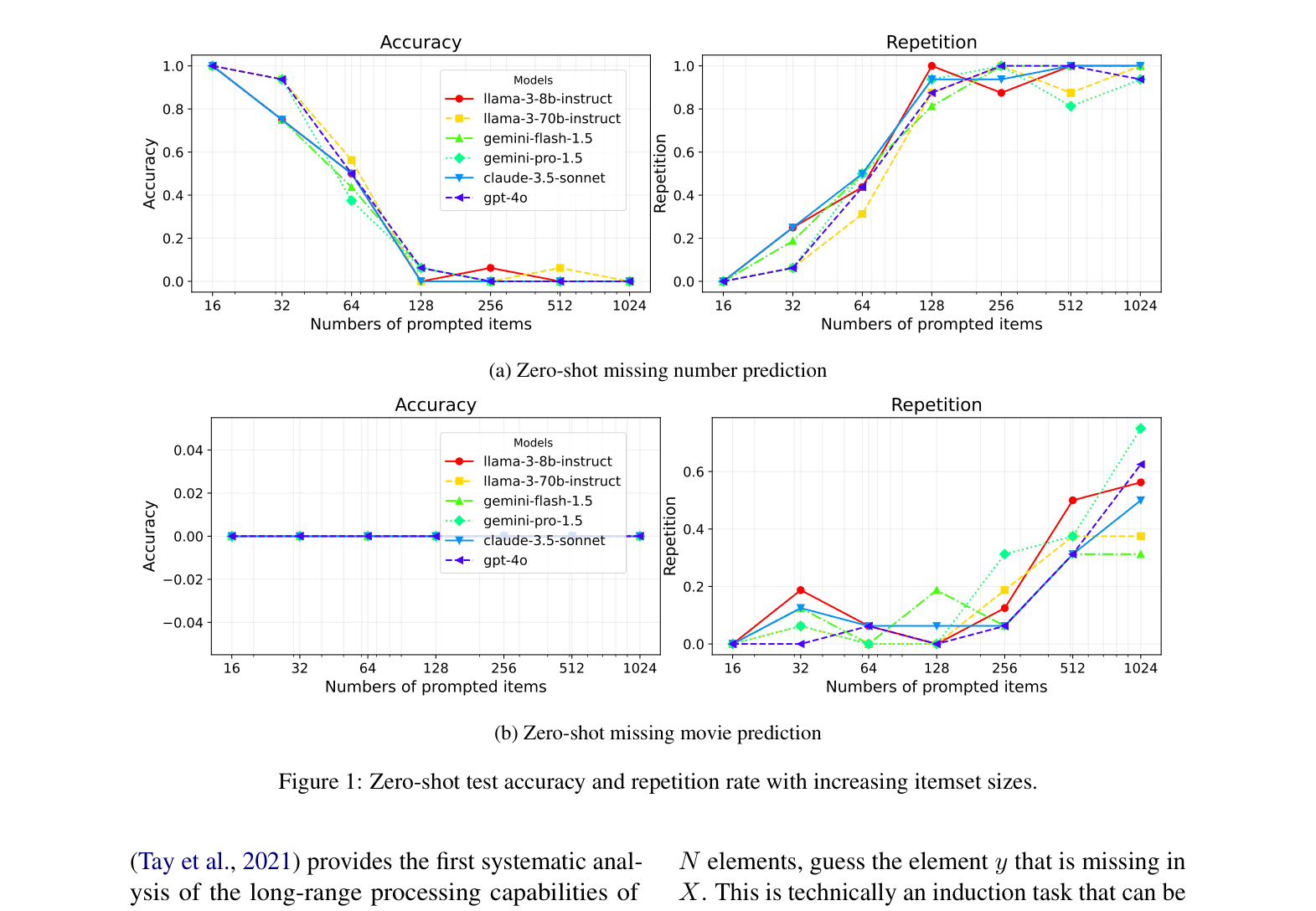
Accuracy and Repetition Rate vs. Number of Prompted Items for various LLMs (Llama-3, Gemini, Claude, GPT-4o)
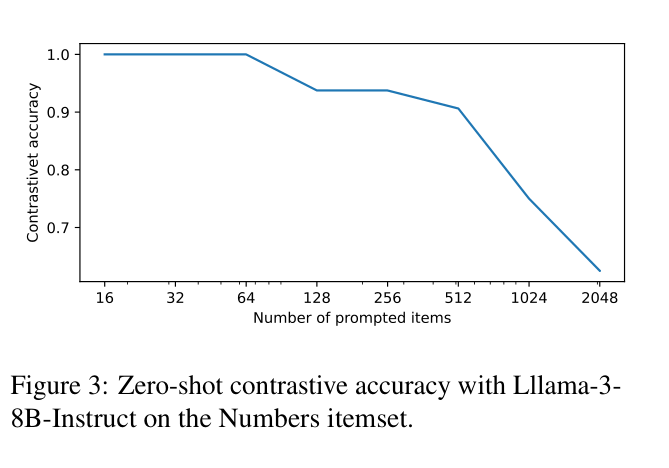
Contrastive Accuracy ('Is item i in list?') vs. Number of Items for Llama-3-8B
Main Takeaways
- Performance collapse: All tested mid-2024 flagship models (Llama-3, Gemini, GPT-4o) show sharp degradation in missing item prediction when input lists exceed ~100-256 items.
- The 'Blur' effect: High contrastive accuracy (75%) vs. near-zero generative accuracy at 1024 items suggests the core issue is not context encoding, but 'attention overflow' during the generation phase where the model must attend to all items simultaneously.
- Generalization failure: Fine-tuning helps on the specific training distribution (small lists) but fails to generalize to longer lists or different domains, suggesting a structural architectural limitation rather than a data lack.