📝 Paper Summary
Conversational Recommendation Systems
Preference Elicitation (PE)
Bayesian Optimization
PEBOL formulates natural language preference elicitation as a Bayesian Optimization problem, using Natural Language Inference to update beliefs and Thompson Sampling to guide LLMs in generating strategic queries.
Core Problem
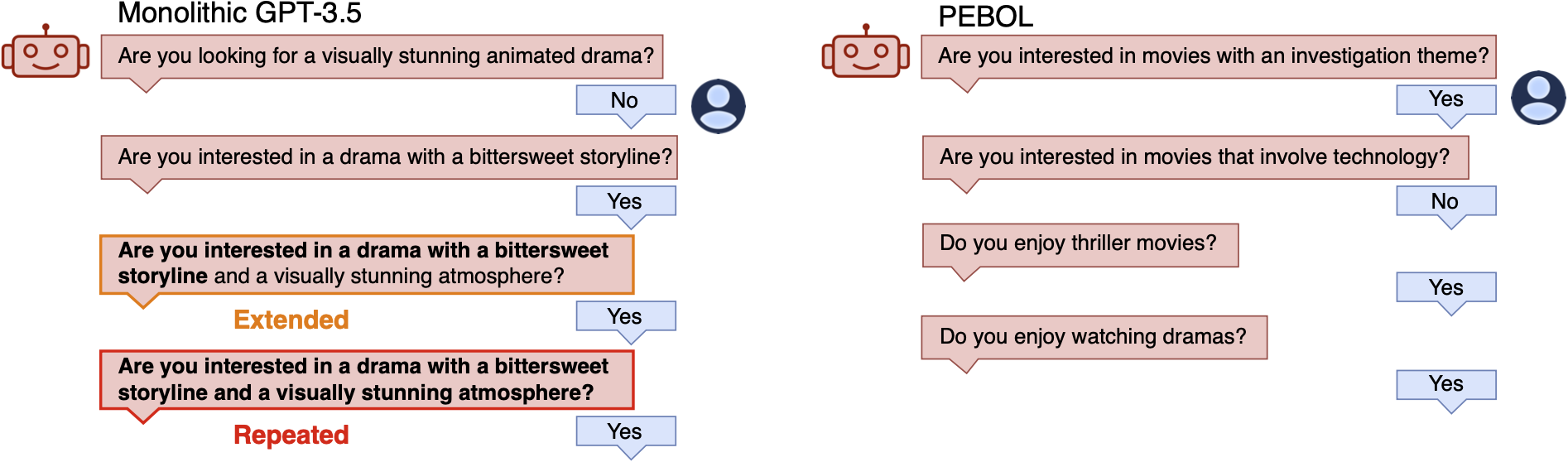
Monolithic LLMs lack the decision-theoretic reasoning to balance exploration and exploitation in dialogues, while traditional Bayesian methods cannot handle natural language inputs or generate fluent queries.
Why it matters:
- Current LLM-based recommenders often over-exploit known preferences or waste turns on irrelevant items due to a lack of formal lookahead planning
- Providing all item descriptions to an LLM's context window for reasoning is computationally prohibitive for large catalogs
- Traditional preference elicitation requires explicit ratings or comparisons, which are unnatural for users unfamiliar with the item set
Concrete Example:
In a cold-start movie recommendation, a standard LLM might randomly ask 'Do you like comedy?' (inefficient). A traditional Bayesian system might ask 'Rate movie ID #593' (unnatural). PEBOL's Bayesian policy selects the most informative item (e.g., *The Matrix*), prompts the LLM to ask 'What do you think of sci-fi action movies like The Matrix?', and uses the user's text response to mathematically update probabilities for all similar movies.
Key Novelty
PEBOL (Preference Elicitation with Bayesian Optimization augmented LLMs)
- Replaces the 'black box' reasoning of LLMs with a formal Bayesian Optimization loop (Thompson Sampling/UCB) to select which item to discuss next
- Uses the LLM only as a 'translator': it converts the mathematically selected item into a natural language query and doesn't need to see the full item catalog
- Employing a Natural Language Inference (NLI) model as a likelihood function, converting unstructured text responses into numerical probability updates for item utilities
Architecture
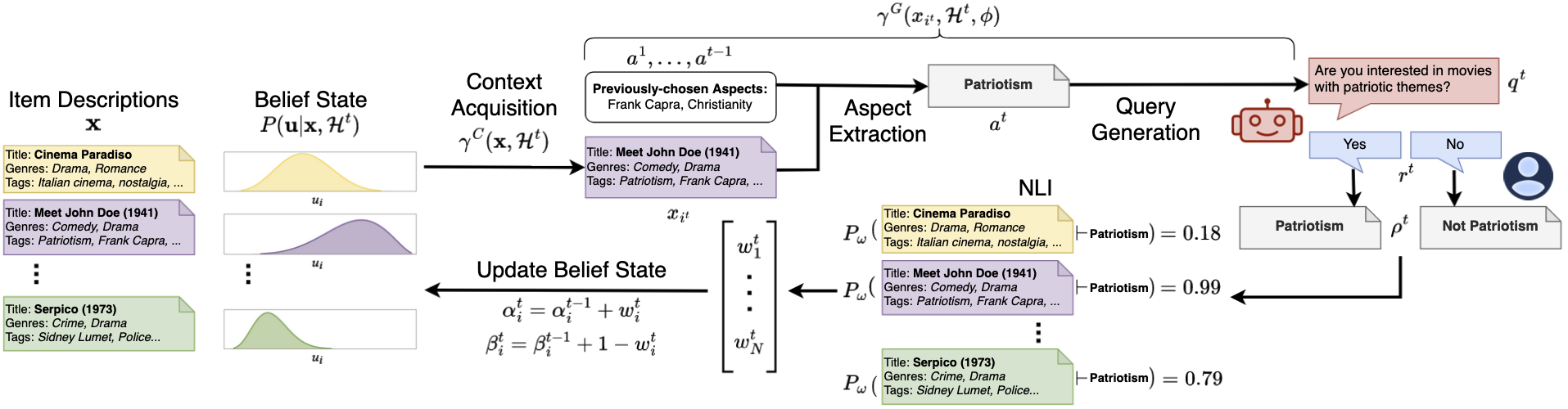
The iterative PEBOL workflow combining Bayesian belief updates with LLM query generation
Evaluation Highlights
- +0.096 MRR@10 improvement (0.270 vs 0.174) over GPT-3.5 on the MovieLens-25M dataset after 10 dialogue turns
- Achieves ~3x higher MRR@10 on the Amazon Books dataset (0.134) compared to GPT-3.5 (0.046)
- Outperforms purely random selection strategies significantly (0.270 vs 0.003 MRR@10 on Movies), proving the value of the Bayesian selection strategy
Breakthrough Assessment
7/10
Novel bridging of rigorous Bayesian Optimization with the generative capabilities of LLMs for cold-start recommendation. Solves the context-window scaling issue nicely, though relies on simulated user evaluation.