📝 Paper Summary
Industrial Recommendation Systems
Multi-modal User Sequence Modeling
QARM V2 aligns LLMs with recommendation goals by filtering training data via reasoning models and generating hybrid quantized Semantic IDs that combine data-adaptive clustering with collision-free scalar quantization.
Core Problem
Traditional ID-based recommendation systems lack semantic understanding and generalization, while direct use of LLM embeddings suffers from misalignment with business objectives (Representation Unmatch) and difficulty in end-to-end optimization (Representation Unlearning).
Why it matters:
- Standard ID embeddings discard knowledge when items go offline (Knowledge Isolation) and fail to capture fine-grained semantics beyond coarse tags
- Directly using pre-trained LLM embeddings fails because LLM objectives (captioning) differ from RecSys goals (click prediction); e.g., visually similar items may have different usage scenarios
- Freezing LLM embeddings prevents RecSys from adapting to dynamic user preferences, while fine-tuning billion-parameter LLMs end-to-end in real-time is computationally prohibitive
Concrete Example:
A standard retrieval model might link 'soy sauce' and 'laundry detergent' due to exposure bias (both are popular), or 'toothpaste' and 'ointment' due to similar tube packaging. QARM V2 uses a reasoning LLM to reject these illogical pairs, ensuring embeddings reflect true underlying usage relationships.
Key Novelty
Reasoning-Aligned Embedding & Hybrid Res-KmeansFSQ Quantization
- Uses a 'Reasoning Item Alignment' mechanism where a reasoning LLM filters noisy training pairs (e.g., popular but unrelated items) to ensure embeddings capture true business logic
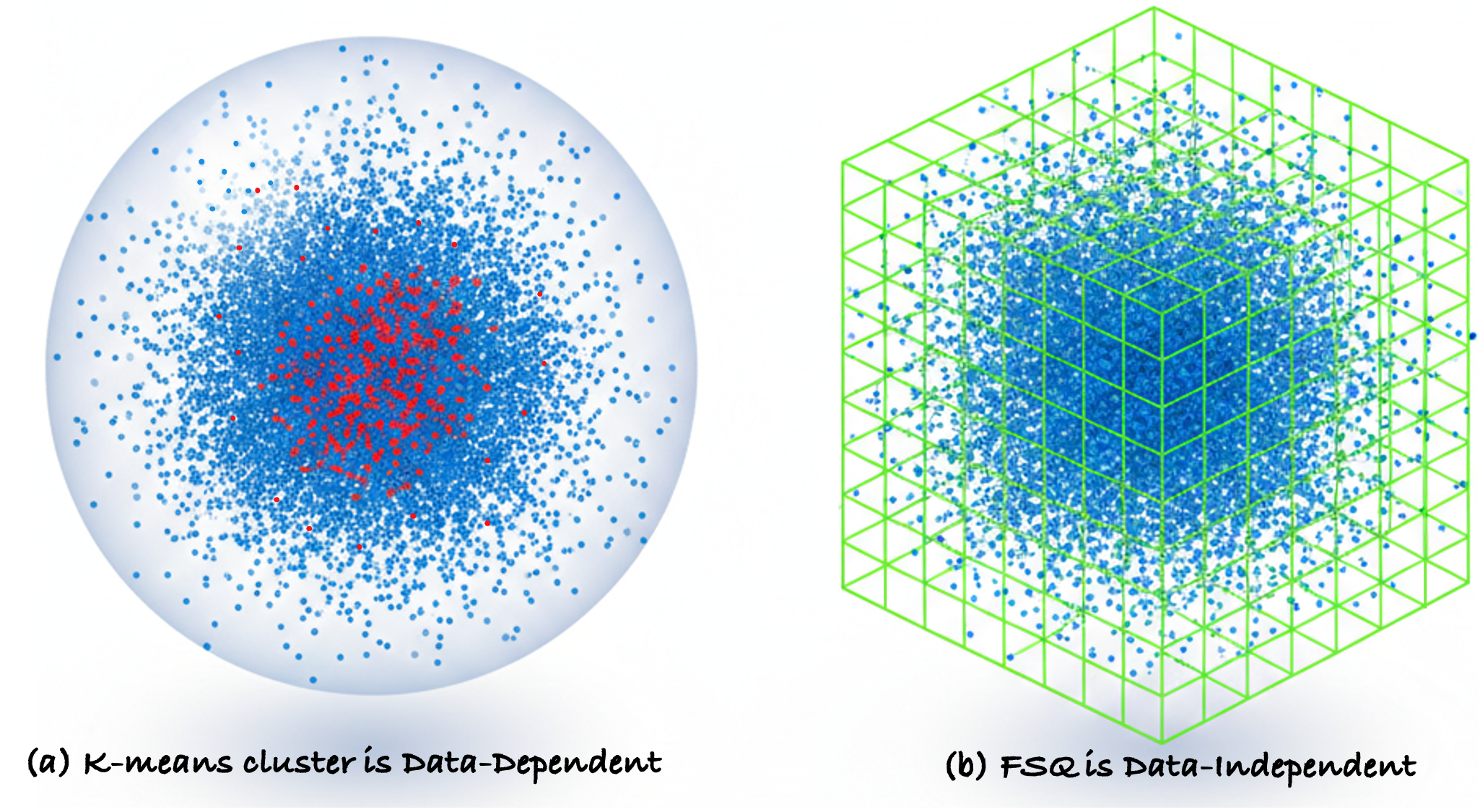
- Introduces 'Res-KmeansFSQ', a hybrid quantization method that uses K-means for coarse categorization (first 2 layers) and Finite Scalar Quantization (FSQ) for fine-grained details (last layer), preventing codebook collisions in long-tail data
Architecture
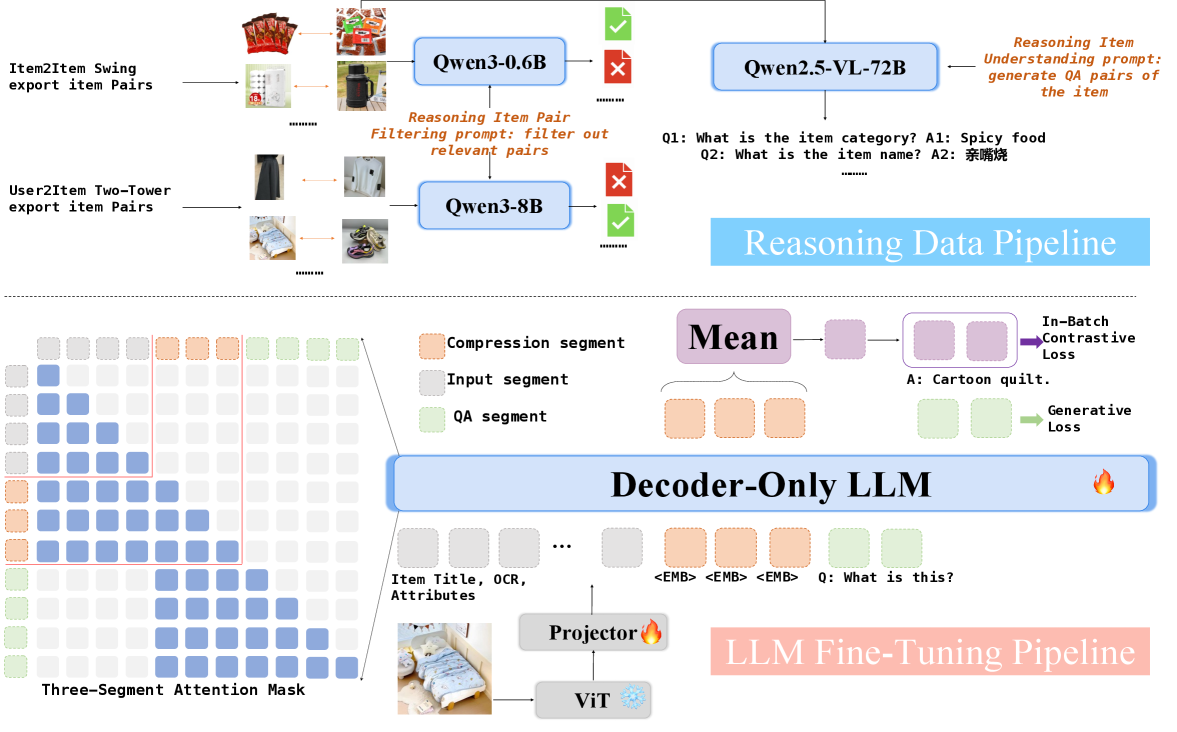
The 3-segment LLM training strategy for generating embeddings while maintaining text generation capabilities.
Evaluation Highlights
- Rejecting 10%+ of Item2Item pairs and 70%+ of User2Item pairs during data construction significantly reduces noise from exposure bias
- Deployed on Kuaishou's platform serving 400 million daily active users across shopping, advertising, and live-streaming scenarios
- Reduces codebook collisions in the Shopping scenario compared to naive Res-Kmeans (where >30% of IDs had multiple candidates)
Breakthrough Assessment
8/10
Strong industrial application of LLMs to RecSys. The hybrid quantization (K-means + FSQ) and reasoning-based data cleaning are practical, high-impact innovations for billion-scale systems.