📝 Paper Summary
Sequential Recommendation (SR)
Multimodal Recommendation
Large Language Models (LLMs) for Recommendation
MME-SID integrates multimodal embeddings and initializes semantic IDs with trained code embeddings to prevent the loss of distance information and dimension collapse in LLM-based recommendation.
Core Problem
LLM-based Sequential Recommendation suffers from embedding collapse (mapping low-rank collaborative embeddings to high-dimensional space) and catastrophic forgetting (losing distance information when learning semantic IDs).
Why it matters:
- Blindly mapping pre-trained recommendation embeddings to LLMs causes efficient capacity usage (collapse), limiting scalability
- Standard quantization methods (like TIGER) discard trained code embeddings and re-learn from scratch, losing over 94% of the geometric distance information essential for recommendation accuracy
- Existing multimodal encoders often misalign text and vision spaces or fail to handle complex item descriptions
Concrete Example:
In a standard approach, if a user interacts with items A and B, and buys C, the model should know C is closer to A/B. When using standard randomly initialized semantic IDs, the model forgets this: the Kendall's tau (rank correlation of distances) drops from 0.3714 to 0.0550, indicating 94.5% of the learned distance structure is lost.
Key Novelty
Multimodal Embeddings with Initialized Semantic IDs (MME-SID)
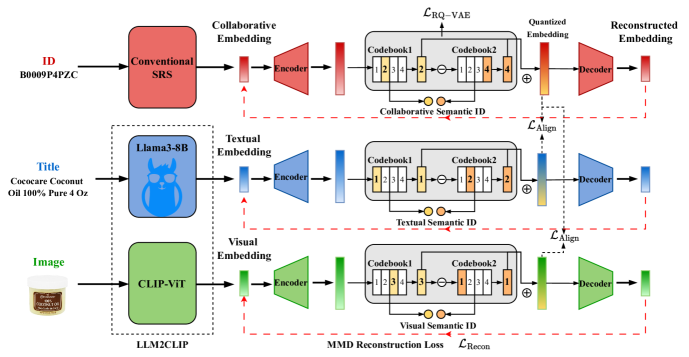
- Uses a Multimodal Residual Quantized VAE (MM-RQ-VAE) that employs Maximum Mean Discrepancy (MMD) loss instead of MSE to explicitly preserve the statistical distribution of the original embeddings
- Initializes the LLM's input token embeddings using the *trained codebook embeddings* from the quantization step, rather than random initialization, to retain learned distance information
- Incorporates a frequency-aware fusion module that dynamically weights the importance of text, visual, and collaborative modalities based on how often an item appears (head vs. tail)
Architecture
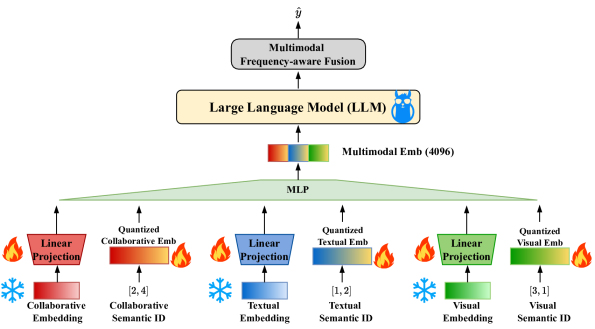
The two-stage framework of MME-SID: (1) Encoding stage generating multimodal embeddings and semantic IDs, and (2) Fine-tuning stage for the LLM.
Evaluation Highlights
- Demonstrates that standard random initialization of semantic IDs results in a catastrophic forgetting rate of 94.50% (measured by Kendall's tau drop to 0.0550)
- Shows that linear projection of collaborative embeddings into LLM space causes over 98% of the embedding matrix dimensions to collapse (become negligible singular values)
- The proposed quantization preserves 37.14% of the original distance ordering information (Kendall's tau) compared to the baseline's near-zero preservation
Breakthrough Assessment
7/10
Strong theoretical diagnosis of why LLM4Rec fails (collapse/forgetting) and a well-motivated architectural fix. While the performance metrics are cut off in the provided text, the analysis of embedding rank and distance preservation is novel.