📝 Paper Summary
Proactive Intent Prediction
Chatbot Recommendations
LLM Alignment for Recommendation
RGAlign-Rec aligns an LLM's semantic reasoning with downstream ranking objectives by using a query-enhanced ranking model as a reward signal for refining the LLM's latent query representations.
Core Problem
In chatbot recommendations, there is a semantic gap between discrete user features and fine-grained intents, and a misalignment between general LLM objectives (fluency) and task-specific ranking goals (CTR).
Why it matters:
- Standard recommendation models rely on ID-based collaborative signals, failing to capture the semantic nuance of service issues in zero-query chatbot settings.
- General-purpose LLMs produce representations optimized for human readability, which are often sub-optimal for ranking metrics like Click-Through Rate.
- Proactive prediction of user intent (e.g., delivery delays) is critical for reducing friction in customer service chatbots handling millions of daily interactions.
Concrete Example:
A user has an order stuck in 'To Receive' for 7 days. A standard model sees discrete IDs and might miss the urgency. A general LLM might describe the issue fluently ('The user is waiting') but fail to map it to the specific KB intent 'Speed up parcel delivery' because the embedding isn't aligned with the ranking space.
Key Novelty
Closed-Loop Ranking-Guided Alignment (RGA)
- Treats the recommendation ranking model as a Reward Model (RM) to provide feedback to the LLM reasoner, rather than relying on human preference labels.
- Introduces a 'Query-Enhanced' three-tower architecture where an LLM synthesizes a latent query from user history, which is then explicitly aligned with item and user towers.
- Uses a multi-stage alignment process: first training the ranker, then using the ranker to select best-of-N LLM queries for supervised fine-tuning and contrastive learning.
Architecture
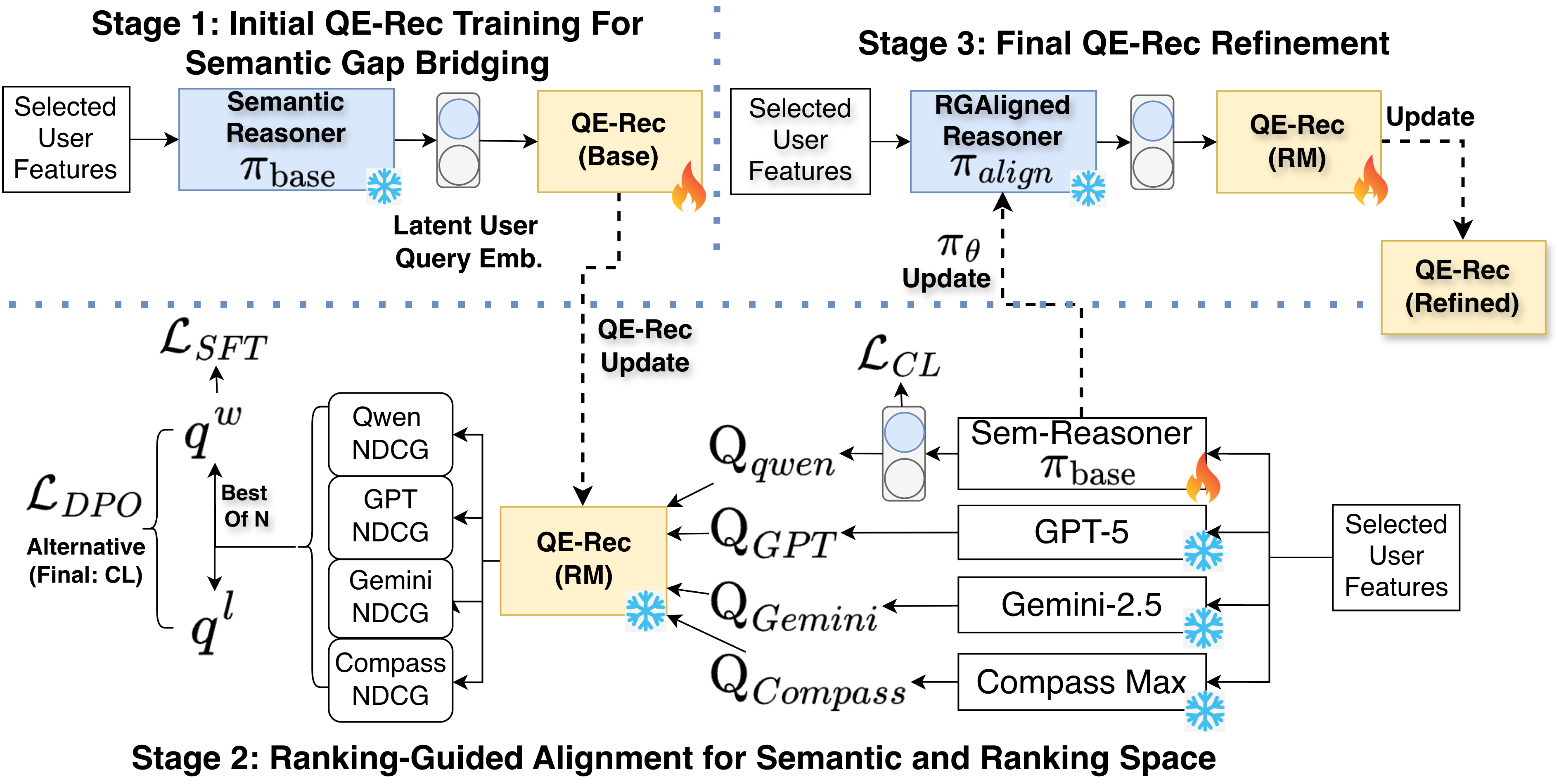
The three-stage RGAlign-Rec framework: (1) Training QE-Rec with a frozen LLM, (2) Ranking-Guided Alignment (RGA) where the QE-Rec acts as a Reward Model to select best teacher queries for LLM fine-tuning, and (3) Re-training QE-Rec with the aligned LLM.
Evaluation Highlights
- +0.12% absolute GAUC improvement on a large-scale Shopee industrial dataset, representing a 3.52% relative reduction in error rate.
- +0.98% CTR improvement in online A/B testing from the Query-Enhanced model alone, with an additional +0.13% gain after Ranking-Guided Alignment.
- +0.56% improvement in Recall@3 compared to strong baselines like DIN and SASRec.
Breakthrough Assessment
7/10
Solid industrial application of LLM-for-RecSys. The closed-loop alignment using the ranker as a reward model is a practical, effective strategy for domain-specific alignment without expensive human annotation.