📝 Paper Summary
Recommendation Systems
Representation Learning
The paper replaces random item IDs in ranking models with Semantic IDs—discrete, hierarchical codes derived from content—adapted via SentencePiece tokenization to improve generalization on new items while maintaining memorization.
Core Problem
Randomly hashed item IDs allow efficient memorization but fail to generalize to new or long-tail items, while pure content embeddings often degrade overall ranking quality due to poor memorization.
Why it matters:
- Industrial recommender systems (e.g., YouTube) deal with billions of dynamic items; pure ID approaches struggle with the 'cold-start' problem for new uploads
- Replacing IDs with raw content embeddings often causes a drop in quality because dense vectors lack the item-level memorization capacity of discrete ID embedding tables
- Existing solutions like end-to-end video encoders (VideoRec) are computationally prohibitive (10-50x cost) for latency-sensitive production ranking
Concrete Example:
A new video uploaded to YouTube has no interaction history, so a random ID embedding cannot capture its properties. However, using its raw visual embedding might blur it with thousands of similar videos, losing the specificity needed to rank it precisely for a user.
Key Novelty
Semantic IDs (SIDs) with SentencePiece Adaptation
- Use a frozen RQ-VAE (Residual-Quantized VAE) to compress content embeddings into a sequence of discrete integers (Semantic IDs) that capture hierarchical concepts
- Adapt these Semantic ID sequences for ranking models using SentencePiece Model (SPM) tokenization, which learns variable-length sub-word units to hash items effectively, balancing granularity (memorization) and sharing (generalization)
Architecture
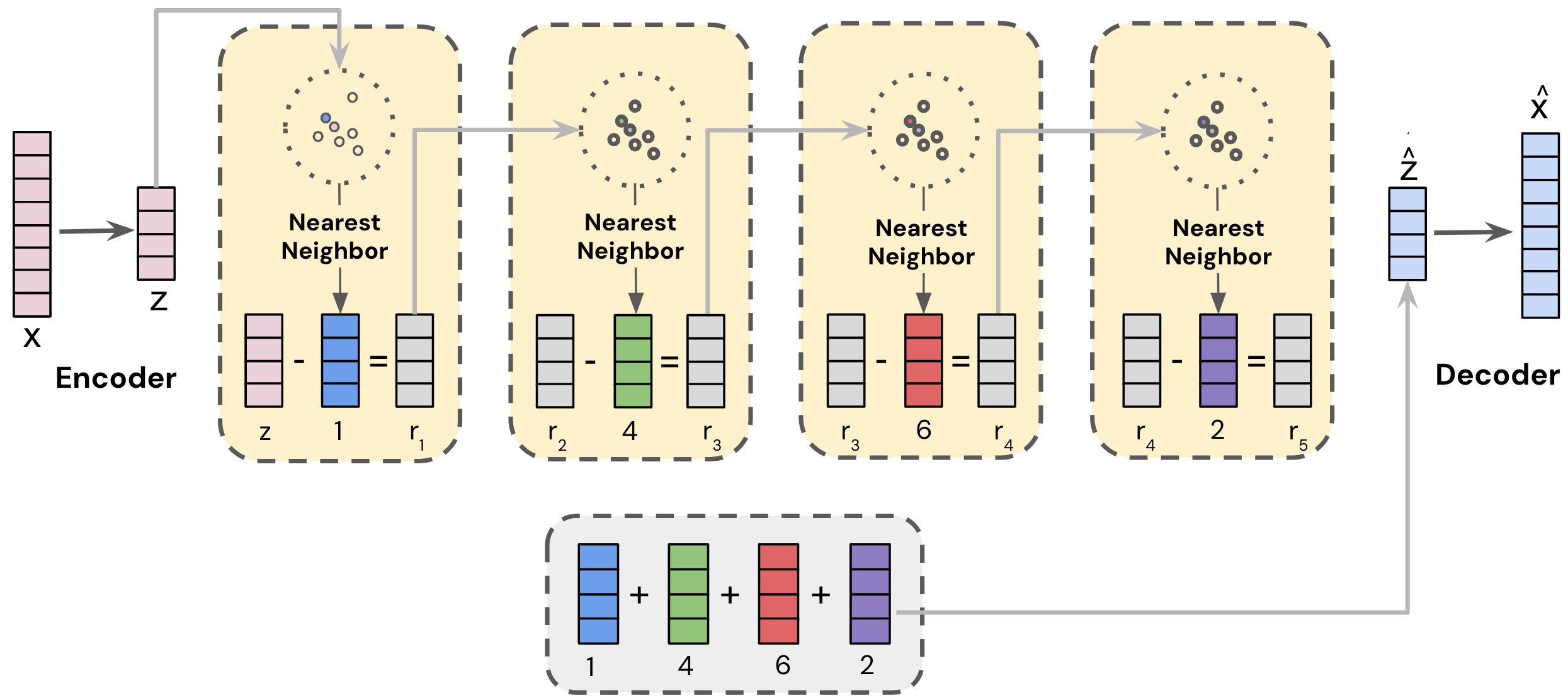
The RQ-VAE (Residual-Quantized Variational AutoEncoder) architecture used to generate Semantic IDs.
Evaluation Highlights
- Demonstrates that SentencePiece Model (SPM) adaptation outperforms N-gram adaptation for Semantic IDs in industry-scale ranking
- Qualitatively reported to improve generalization on new and long-tail item slices in YouTube production without sacrificing overall model quality (specific numbers not in provided text)
Breakthrough Assessment
7/10
Offers a practical, compute-efficient strategy for integrating content semantics into large-scale ID-based rankers. Bridges the gap between ID memorization and content generalization.