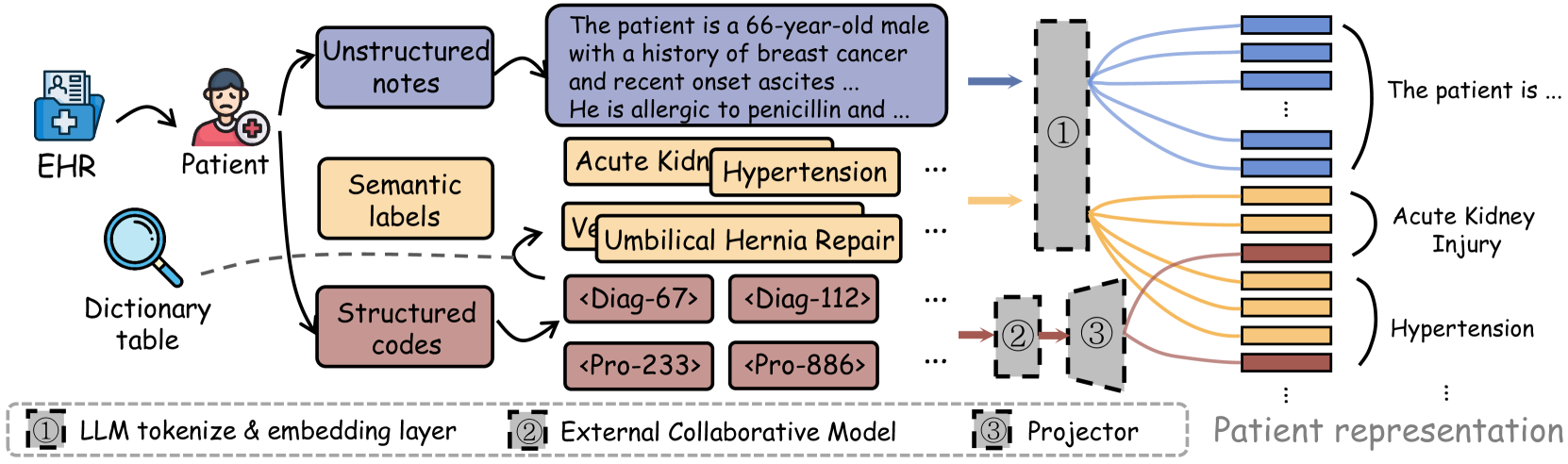
📝 Paper Summary
Medication Recommendation
Clinical LLM Alignment
RLHF for Healthcare
FLAME reframes medication recommendation as a sequential list-generation task, using step-wise Group Relative Policy Optimization (GRPO) to align LLMs with fine-grained safety and accuracy rewards.
Core Problem
Existing medication recommendation systems rely on point-wise predictions that evaluate drugs independently, failing to capture synergistic effects and adverse drug-drug interactions (DDIs) inherent in complex prescriptions.
Why it matters:
- Clinicians must balance therapeutic efficacy with cumulative safety risks in multimorbidity cases, which point-wise models cannot naturally model.
- Standard LLM alignment methods (like vanilla GRPO) assign rewards only to complete sequences, making it difficult to credit individual drug decisions within a long prescription list.
Concrete Example:
A point-wise model might select Drug A and Drug B because both score highly for a patient's diagnosis individually, overlooking that the combination (A+B) causes a severe adverse interaction. FLAME generates the list sequentially, allowing the policy to be penalized immediately when Drug B is added to a list containing Drug A.
Key Novelty
Step-wise Group Relative Policy Optimization (Step-wise GRPO)
- Decomposes the generation of a drug list into a sequence of state transitions (adding/removing a drug), rather than treating the whole list as a single action.
- Applies potential-based reward shaping to provide dense, token-level feedback for each drug addition, calculating the incremental change in safety and accuracy at every step.
Architecture
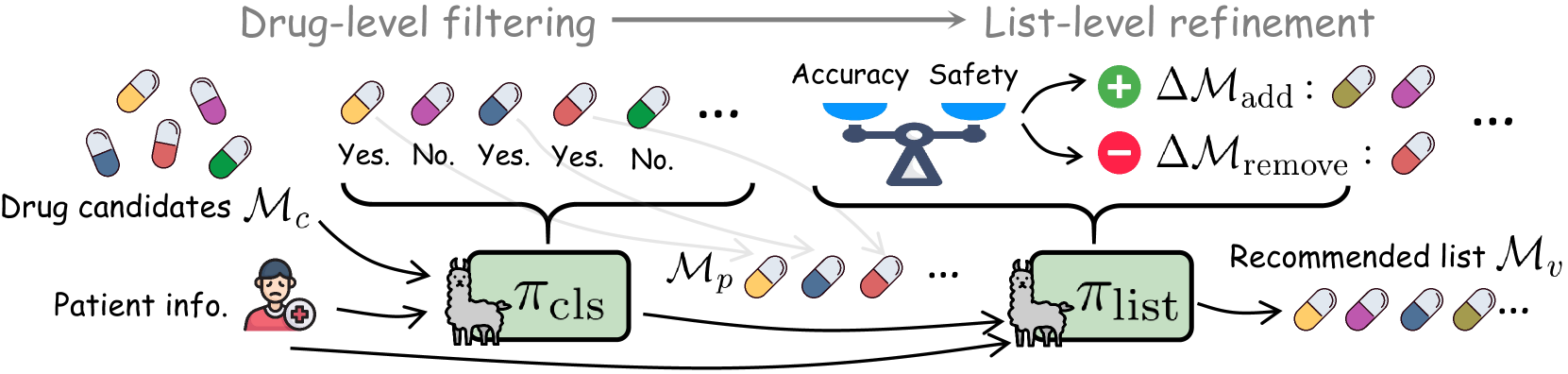
The two-stage inference framework of FLAME: Drug-level filtering followed by List-wise refinement.
Evaluation Highlights
- Achieves state-of-the-art accuracy on MIMIC-III, MIMIC-IV, and eICU benchmarks compared to both longitudinal models (e.g., MoleRec) and LLM baselines (e.g., LAMO).
- Significantly reduces DDI rates while maintaining high Jaccard accuracy, demonstrating a controllable safety-accuracy trade-off.
- Demonstrates strong generalization across different institutions and time periods, validating adaptability to diverse clinical settings.
Breakthrough Assessment
8/10
Significantly advances clinical LLM application by moving from point-wise to list-wise reasoning with a novel, theoretically grounded RL alignment method (step-wise GRPO) that explicitly handles safety constraints.