📝 Paper Summary
LLM-enhanced Recommendation
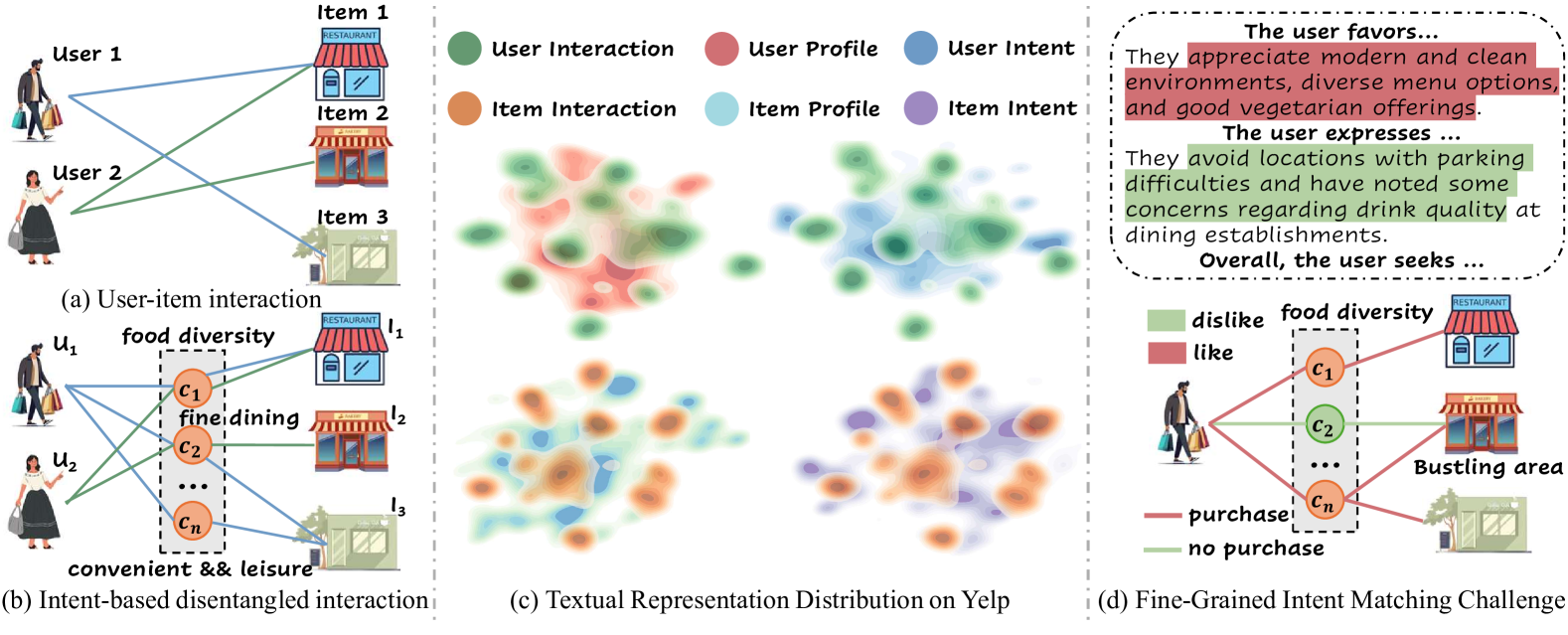
Intent Disentanglement
IRLLRec aligns explicit textual intents from LLM summaries with implicit behavioral intents from interaction graphs using dual-tower contrastive learning and momentum distillation to improve recommendation accuracy.
Core Problem
Existing intent-based recommenders struggle to align the distinct representation spaces of textual data (reviews/descriptions) and interaction data (clicks), often leading to noise and misalignment.
Why it matters:
- Implicit interaction data is sparse and noisy, often failing to capture fine-grained user motivations (e.g., buying for 'skin sensitivity' vs. generic popularity).
- Rich textual data contains explicit preferences but exists in a different semantic space than collaborative filtering signals, making direct fusion difficult.
- Mismatched intents across modalities result in suboptimal recommendations, as behavioral drivers (interactions) and expressed preferences (text) may diverge or contain unique noise.
Concrete Example:
A user might interact with a restaurant (implicit intent: busy location) but write a review praising 'diverse menu options' (explicit intent). Current models struggle to match these distinct signals; noise like 'parking difficulties' in text might be irrelevant to the core interaction driver, confusing the recommender.
Key Novelty
Dual-Tower Intent Alignment & Momentum Distillation
- Uses a dual-tower architecture to separately encode textual intents (via LLM summaries) and interaction intents (via Graph Neural Networks), then forces them into a shared space using contrastive alignment.
- Employs a momentum-based teacher-student framework (Interaction-Text Matching) where evolving teacher encoders guide student encoders to identify and match key latent intents, filtering out noise.
- Introduces 'Translation Alignment' which adds noise perturbations to representations to make the alignment robust against inherent input feature noise.
Architecture
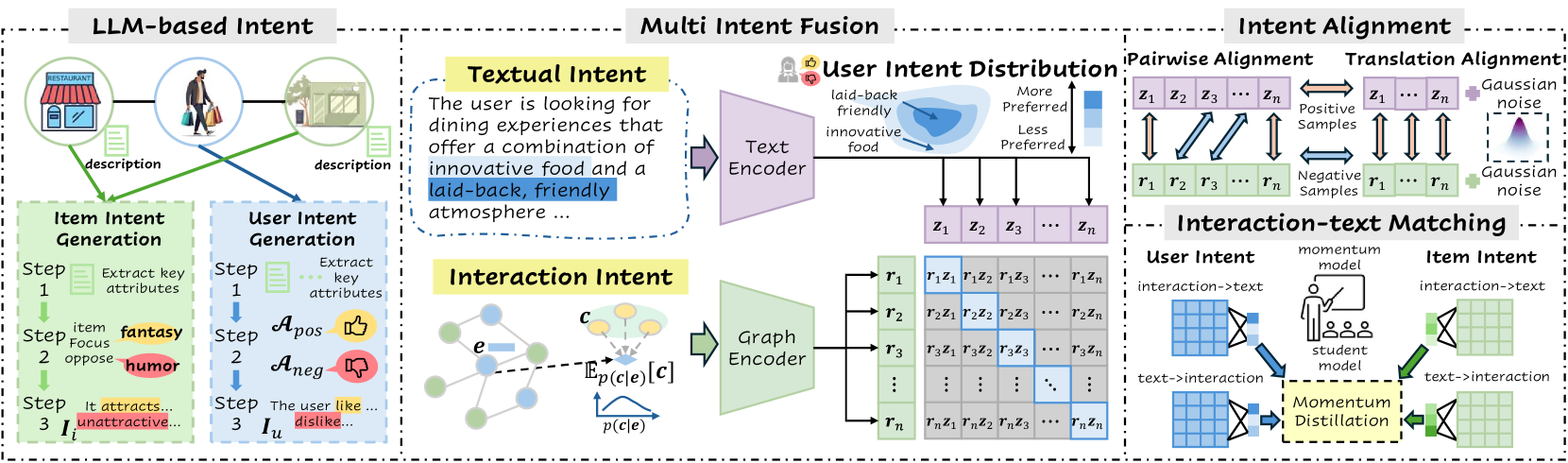
The overall IRLLRec framework, detailing the flow from multimodal inputs (text and graph) to intent extraction, dual-tower encoding, alignment strategies, and final prediction.
Evaluation Highlights
- Outperforms state-of-the-art baselines (including RLMRec and DCCF) on three public datasets (Amazon-Book, Yelp, Steam) across Recall and NDCG metrics.
- Achieves significant performance gains in sparse data scenarios, demonstrating the benefit of supplementing interactions with textual intent.
- Ablation studies confirm that both the Intent Alignment (IA) and Interaction-Text Matching (ITM) modules are critical, with removal leading to performance drops.
Breakthrough Assessment
7/10
Solid contribution to multimodal recommendation by effectively combining LLM-based text summarization with GNN-based collaborative filtering via novel alignment and distillation techniques. While the components (CL, distillation) are known, the specific application to intent disentanglement is well-executed.